Um processo de levantamento de informações é em geral caro e em muitas situações é destrutivo. Os processos destrutivos são em geral associadosa equipamento eletrônicos, para saber quanto uma lâmpada dura tenho que ligar e esperar queimar!! Em ciências sociais estamos interessados em características de pessoas, empresas, municípios, estados, países etc. Não é destrutivo mas é uma coleta cara. Por exemplo, o Censo demográfico de 2010 custou R$ 1,3 bilhões, ou aproximadamente R$ 2,2 bi em reais de 2020. O valor é de aproximadamente R$ 35,00 por domicílio. Vejamos outro caso. A figura abaixo mostra a nota de pesquisa eleitoral realizada para eleição ao governo de São Paulo. Vejam que os questionários variam de R$40 a R$67 por questionário, uma média de R$ 53 reais o questionário. Logo uma pesquisa eleitoral para saber as intenções de votos de 2500 pessoas custa aproximadamente R$135 mil1.
Figure 10.1: Valor de pesquisa eleitoral em 2018
Espero que tenha ficado claro que olhar todo mundo, na grande maioria das vezes, é fisicamente, temporalmente e financeiramente impossível.
Dessa forma nosso objetivo aqui é:
A partir de uma amostra da população realizar inferência sobre toda a população.
10.1.1 Exemplos do príncipio no dia a dia
Pense nessas situações:
Para medir a glicose muitos pacientes usam uma gota de sangue e um pequeno aparelho. A partir dele sabem quanto tem no corpo todo, basta uma gota para termos boa certeza de quanto é taxa de glicose!
Para saber se a quantidade de sal está adequada em uma grande panela de arroz, basta uma pequena colher de chá para termios uma boa certeza!
Abacaxis às vezes são vendidos em caminhões na rua. Quando paramos provamos e são doces. Compramos 4 por 10. Qual a certeza que esses que vc está levando estejam também doces? É diferente das situações anteriores?
Com certeza vc deve ter pensado que sim é diferente. A certeza é muito menor na segunda. A diferença está em quão homogênea é a característica na população, o sal no arroz e a glicose no sangue devem ser muito bem distribuidas, ou seja, bem homogêneas. Já a doçura no abacaxi deve ter distribuição pior e provar apenas um abacaxi não nos dá uma ideia do todo.
Esse é um erro muito comum, a partir de uma ou poucas observações dizer que o todo se comporta da mesma maneira, esse erro se agrava quando maior é a heterogeneidade!!!
10.2 Algumas definições importantes
10.2.1 População e amostra
NoteDEFINIÇÃO
População: Totalidade das observações sob Investigação
Amostra: Subconjunto da população observado
A definição da população depende da pergunta de pesquisa ou análise. Se queremos saber qual o salário médio dos empregados do setor industrial no estado de São Paulo para determinado ano, nossa população são todos os funcionários das indústrias instaladas no estado de São Paulo para esse ano. Se queremos os determinantes do desempenho escolar dos alunos do ensino fundamental no Brasil em 2019, nossa população será esse grupo de aluno nesse ano. Se quisermos avaliar o gasto municipal no ano anterior as eleições no Brasil, temos nossa população formada pelos municípios para o ano de análise.
Quem define a população é o objetivo do seu trabalho
10.2.2 Amostragem Aleatória Simples
Existem várias maneiras de fazer uma análise aleatória, uma delas é a simples. Vejamos primeiro um processo de amostragem não aleatório e que possui tendenciosidade. A figura abaixo mostra esse processo2:
Figure 10.2: Amostragem tendenciosa
Observa-se que existe uma supervalorização do verde e uma subvalorização do vermelho. Chegariamos a conclusão, caso isso fosse uma pesquisa eleitoral, que o candidato verde, segunda amostra teria mais chance de ganhar e o vermelho menor chance. O que não condiz com a população. Dizemos que temos uma amostra viesada ou tendenciosa.
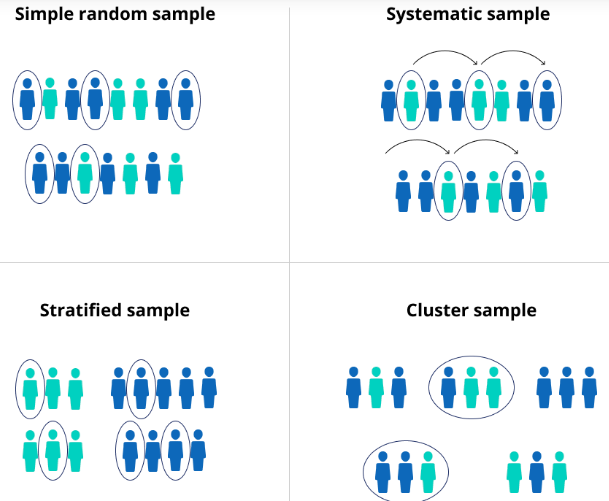
Um processo de amostragem aleatório requer que as características presentes na população estejam presentes na amostras e estejam balanceadas, ou seja, que a sua leitura represente bem o todo. a figura abaixo mostra alguns tipos de amostragem, a simples, sistemática, estratificada e em cluster3.
Figure 10.3: Tipos de amostragem aleatórias
Aqui podemos pensar sempre na amostragem aleatória simples e que será explicada nesse curso. Outros porcessos de amostragem requerem estudos específicos na área! Vejamos então a definição de amostragem aleatória simples.
NoteDEFINIÇÃO
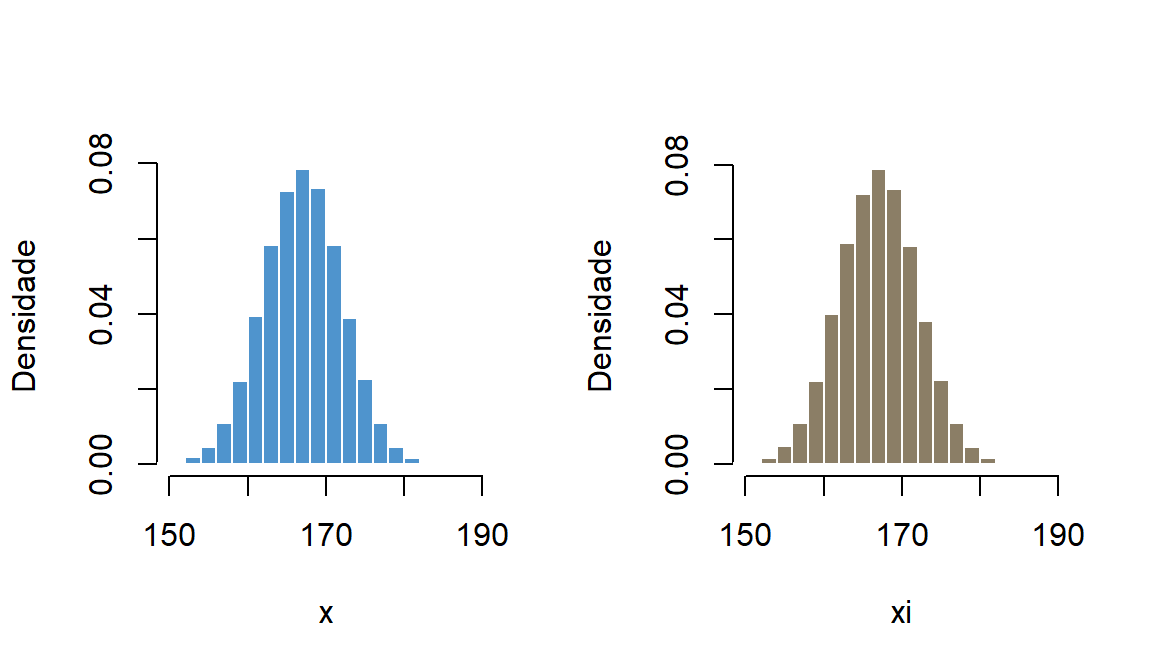
Considere uma amostra de tamanho n de uma população \(f(X)\),tal que \(i=1,...,n\), onde \(X_i\) é a i-ésima medição de \(X\).
Assim, chamamos de Amostra Aleatória Simples o conjunto de n variáveis aleatóridas independentes \(X_i,...,X_n\), cada uma com a mesma distribuição de probabilidade de \(X\), ou seja, \(f(X)\).
Precisa-se garantir que cada medida \(X_i\) seja feita da mesma maneira ou da mesma forma de mensuração. Dessa forma, garante-se que a Amostra Aleatória Simples \(X_i,...,X_n\) é independemente e identicamente distribuída (iid). Portanto, \(X_i\) são variáveis aleatórias e \((x_i, ..., x_n)\) os valores correspondentes.
Graficamente:
# Mostrando que Xi tem a mesma distribuição de X# Simulamos a distribuição de alturas, X, E(X)=167 e DP(X)=5 x_alt<-rnorm(100000,mean=167, sd=5)# Vamos fazer a primeira medição de X, ou seja, sortear somente o # primeiro elemento Xi. # Iremos repetir a primeira medição 100.000, ou seja, repetimos o # sorteio de Xi 100 mil vezes# 1 - Criamos uma vetor numéricoxi<-numeric()# 2 - Sorteamos de X os valores com reposição e criamos o vetor Xifor ( i in1:100000){ xi[i]<-sample(x_alt,size =1, replace=TRUE)} # 3 - Agora plotamos X e Xi para ver se há diferença na distribuiçãopar(mfrow=c(1,2))hist(x_alt, col="steelblue3", border="white",freq =FALSE, ylab="Densidade",xlab="x",main="", xlim=c(150, 190), breaks=20)hist(xi, col="wheat4", border="white",freq =FALSE, ylab="Densidade",xlab="xi",main="", xlim=c(150, 190),breaks=20)
Distribuição de probabilidade de X e da primeira medição de X, ou seja, Xi
TipEXEMPLO
Seja X a altura média dos alunos da FEA. Temos uma amostra de tamanho n=30 que é representada por:
As medições são (\(X_1, X_2, ..., X_{30}\)) com as respectivas alturas observadas de (\(x_1, x_2,..., x_{30}\))
Se a altura \(X\) for uma v.a. com fdp \(f(x)\) então cada mensuração \(X_i\) terá a mesma distribuição \(f(x)\) e a função de densidade conjunta de (\(X_1, X_2, ..., X_{30}\)) será:
\[g (x_1,...,x_{30})= f(x_1) f(x_2)...f(x_{30})\]
ou
\[q(x_1,...,x_{30})= p(x_1) p(x_2)...p(x_{30})\]
pois são \(iid\).
TipEXEMPLO
Temos uma amostra n=8 de baterias de notebooks, sendo a vida útil dessas representada por X. A primeira medição é \(X_1\) e observa-se o valor \(x_1\) entre todos os possíveis valores. Analogamente:
Tem-se os valores observados (\(x_1, x_2,..., x_{8}\)) das medições (\(X_1, X_2, ..., X_{8}\))
Se a população de notebooks possuem baterias com vida útil normalmente distribuídas \((X)\), então as medições da vida útil (\(X_1, X_2, ..., X_{30}\)) também possuem a mesma distribuição da população original.
10.2.3 Estatística e Parâmetro
NoteDEFINIÇÃO
Parâmetro: Medida que descreve uma característica da população.
Os parâmetros definem as características de uma população. Qual a renda média da população, qual o desemprego médio da população, qual o desempenho médio educacional, qual a expectativa de vida média na população etc. São características que em geral não observamos.
Uma pergunta, qual a nota média da sua turma (aqueles que entraram com você na faculdade)? Perceba que mesmo características da sua população, são de difíceis conhecimento. Temos que nos valer de uma parte e tentar estimar o que seriam os valores dessas características.
NoteDEFINIÇÃO
Estatística é uma característica de uma amostra, ou seja, é uma função de seus elementos \(X_1, X_2, ..., X_{n}\)).
NoteDEFINIÇÃO
Seja \(X_1, X_2, ..., X_{n}\) uma A.A.S. de \(X\). Sejam \(x_1, x_2,..., x_{n}\) os valores medidos a cada para cada medição de \(X\). Seja \(H\) uma função real, cujo argumento é um vetor n-dimensional de números reais. Podemos definir uma estatística como:
\[T= H (X_1, X_2, ..., X_{n}).\]
Para a amostra e toma o valor particular:
\[t= H (x_1, x_2, ..., x_{n}).\]
Onde T é uma variável aleatória e, portanto, possuirá uma distribuição de probabilidade, chamada de distribuição amostral de T. Alguns exemplos de T:
Vejamos a tabela abaixo que já faz uma primeira associação entre estatística e parâmetro:
Parâmetro
Estatística
Esperança
\(E(X)=\mu\)
\(\bar{X}\)
Média
Variância Pop.
\(Var(X)=\sigma^2\)
\(S^2;\sigma^2\)
Variância Amostral
Mediana Pop.
Md
md
Mediana Amostral
Proporção Pop.
p
\(\hat{p}\)
Proporção Amostral
Tabela 1 - Parâmetros populacionais e as Estatísticas associadas
Como regra geral, temos que parâmetros são representados por letras gregas e estatística como letra do nosso alfabeto (latino), ou se utilizamos nosso alfabeto para representar o parâmetro, utilizamos a mesma letra mas com chapéu para indicar que é uma estatística.
10.3 Distribuições amostrais
Nosso objetivo agora é ser mais específico que o colocado anteriormente. Nosso objetivo específico é:
Fazer uma afirmativa sobre o parâmetro, característica da população, por meio de um estatística, característica da amostra.
Ou seja, utilizamos uma estatística amostral \(T\) para inferir o parâmetro populacional \(\Theta\).
Como \(T\) é uma variável aleatória e possui distribuição de probabilidade, precisamos saber:
\(\rightarrow\) Qual a distribuição de T?
\(\rightarrow\) Quais as propriedades ou característica das distribuições amostrais?
10.3.1 Distribuição Amostral da Média
Suponha uma variável aleatória X que possui distribuição de probabilidade f(x) e tem os seguintes parâmetros:
\[E(x)=\mu\]
\[Var(x)=\sigma^{2}\]
Não sabemos qual a distribuição de X, mas sabemos que \(\overline{X}\) é uma uma variável aleatória que é função da amostra e gostariamos de saber sobre algumas características da sua distribuição. Vejamos primeiro os seus momentos. A intuição é:
\(\rightarrow\) Extraímos todas as possíveis amostras de tamanho n da população
\(\rightarrow\) Então calculamos \(\overline{X}\) para cada uma das amostras
Seja \(X\) uma v.a. com parâmetros \(\mu\) e \(\sigma^{2}\). Seja \((X_1, X_2, ..., X_{n})\) uma A.A.S. de \(X\). Então:
\[E(\overline{X})=\mu\]
\[Var(\overline{X})= \frac{\sigma^{2}}{n}\]
Demonstração:
Para \((X_1, X_2, ..., X_{n})\) independentes temos que:
\[E(\overline{X})=\frac{1}{n} \{ E(X_1)+ ...+ E(X_n) \} =\frac{ n \mu}{n}=\mu\]
\[Var(\overline{X})=\frac{1}{n^{2}} \{ Var(X_1)+ ...+ Var(X_n) \}= \frac{1}{n^{2}} n \sigma^{2}= \frac{\sigma^{2}}{n}\]
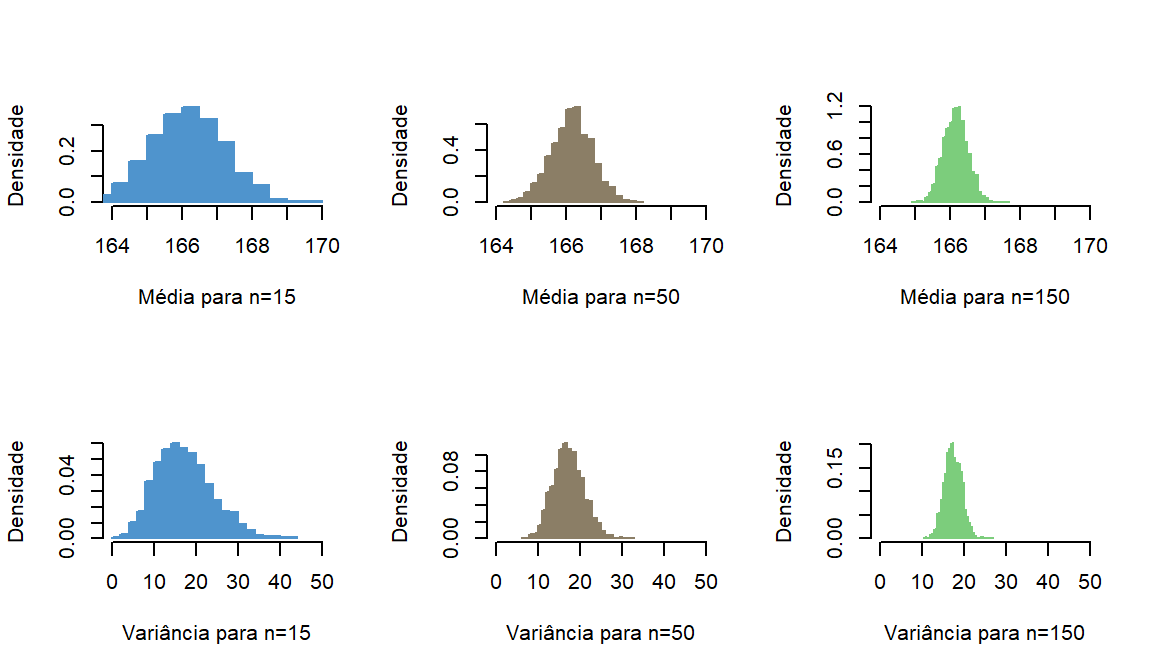
Conforme veremos logo a frente pelo Teorema do Limite Central, que a distribuição de \(\overline{X}\) ser uma \(N(\mu;\frac{\sigma^{2}}{n})\). Dessa forma, quanto maior o \(n\) da amostragem, menor será a \(Var(\overline{X})\). Vejamos a figura abaixo adaptada de Bussab e Morettin:
#Exemplo extraído de Bussab e Morettin# Simulando uma variável com distribuição normal. x_normal<-rnorm(10000,mean=167, sd=5)# Criando os vetores numéricos # Media e variancia para amostras de tam 15, 50 E 150xbar15<-numeric()var_amostral15<-numeric()xbar50<-numeric()var_amostral50<-numeric()xbar150<-numeric()var_amostral150<-numeric()# Extraindo duas mil amostras de 15, 50 e 150 elementos e fazendo a média e # variância para cada uma das amostras. Teremos 2000 médias e 2000 variâncias #para cada tamanho de amostra (15, 50 3 150)for ( i in1:2000){ smp<-sample(x_normal,size =15) xbar15[i]<-mean(x_normal[smp]) var_amostral15[i]<-var(x_normal[smp]) smp<-sample(x_normal,size =50) xbar50[i]<-mean(x_normal[smp]) var_amostral50[i]<-var(x_normal[smp]) smp<-sample(x_normal,size =150) xbar150[i]<-mean(x_normal[smp]) var_amostral150[i]<-var(x_normal[smp])}par(mfrow=c(2,3))hist(xbar15, col="steelblue3",freq =FALSE, breaks =25,main="",xlim=c(164, 170), ylab="Densidade", xlab="Média para n=15",border="steelblue3")hist(xbar50, col="wheat4", freq =FALSE, breaks =25, main="",xlim=c(164, 170), ylab="Densidade", xlab="Média para n=50",border="wheat4")hist(xbar150, col="palegreen3",freq =FALSE, breaks =25, main="",xlim=c(164, 170), ylab="Densidade", xlab="Média para n=150",border="palegreen3")hist(var_amostral15, col="steelblue3", freq =FALSE, breaks =25, main="",xlim=c(0, 50), ylab="Densidade", xlab="Variância para n=15",border="steelblue3")hist(var_amostral50, col="wheat4", freq =FALSE, breaks =25, main="",xlim=c(0, 50), ylab="Densidade", xlab="Variância para n=50", border="wheat4")hist(var_amostral150, col="palegreen3", freq =FALSE, breaks =25, main="",xlim=c(0, 50), ylab="Densidade", xlab="Variância para n=150",border="palegreen3")
Distribuição amostral da média para diferentes tamanos amostrais
Vamos agora calcular as médias para cada uma das variáveis que criamos. Ou seja, vamos fazer a \(E(\overline{X})\)
# Vamos fazer a media das medias calculadas para 15, 50 e 150 com # 2 mil rodadas de amostragemmean(xbar15)
[1] 166.1684
mean(xbar50)
[1] 166.161
mean(xbar150)
[1] 166.1601
Observe que todas ficaram muito próximas da verdadeira esperança da população, mostrando empiricamente o teorema apresentado. Pode-se verificar também a variância amostral \(Var(\overline{X})=\frac{\sigma^{2}}{n}\). Vejamos:
# Vamos fazer a variância das médias calculadas para 15, 50 e 150 com # 2 mil rodadas de amostragemvar(xbar15)
[1] 1.121122
var(xbar50)
[1] 0.3419732
var(xbar150)
[1] 0.119035
Percebemos que a partir que o tamanho amostral vai aumentando o resultado vai convergindo para \(Var(\overline{X})=\frac{\sigma^{2}}{n}\), lembre-se que \(\sigma^{2}=25\) para a simulação feita.
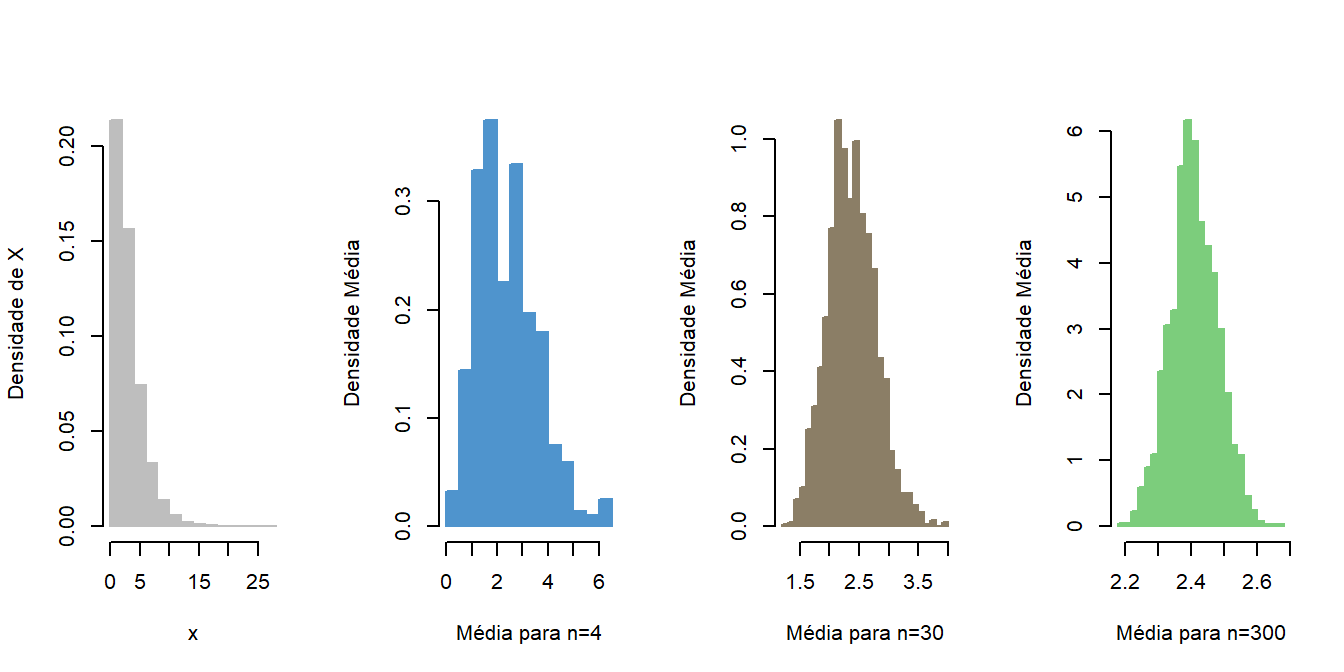
Importante ressaltar que esse resultado para a distribuição da média, ou seja \(\overline{X}\) é valido para qualquer distribuição de \(X\). Veja o caso abaixo onde temos \(X\) que possui uma distribuiçõ \(\chi^2\) com 3 graus de liberdade.
# Distribuição amostral da média quando X tem dist Chi-Quadrado. # Simulando uma distribuição chiquadradox_chisq<-rchisq(100000,df=3)#Inicializando as variaveis como vetores numericos## Media e variancia para amostras de tam 15x_chi4<-numeric()## Media e variancia para amostras de tam 300x_chi30<-numeric()## Media e variancia para amostras de tam 1000x_chi1000<-numeric()for ( i in1:2000){ smp<-sample(x_chisq,size =4) x_chi4[i]<-mean(x_chisq[smp]) smp<-sample(x_chisq,size =30) x_chi30[i]<-mean(x_chisq[smp]) smp<-sample(x_chisq,size =1000) x_chi1000[i]<-mean(x_chisq[smp])}## Figura par(mfrow=c(1,4))hist(x_chisq, col="gray", border="gray",freq =FALSE, main="",ylab="Densidade de X", xlab="x")hist(x_chi4, col="steelblue3", freq =FALSE, breaks =20, main="",ylab="Densidade Média", xlab="Média para n=4",border="steelblue3")hist(x_chi30, col="wheat4", freq =FALSE, breaks =20, main="",ylab="Densidade Média", xlab="Média para n=30", border="wheat4")hist(x_chi1000, col="palegreen3", freq =FALSE, breaks =20, main="",ylab="Densidade Média", xlab="Média para n=300",border="palegreen3")
Distribuição amostral da média para diferentes tamanos amostrais
Podemos observar na figura acima que X é bastante assimétrico. Para o primeiro gráfico tiramos amostra de tamanho 4 e perceba que ainda é assimétrica, mas a partir do momento que vamos aumentando o tamanho da amostra, a distribuição de \(\overline{X}\) vai ficando mais próxima de uma normal.
10.3.2 Distribuição Amostral da Variância
A Variância Amostral também é uma variável aleatória. Os gráficos anteriores mostram a distribuição de \(Var(X_i)\) para diferentes tamanhos amostrais. Importante notar que calculamos na seção anterior também \(Var(\overline{X})\) com base nos valores de média obtidos na simulação. A \(Var(X_i)\) é uma candidata a ser uma boa aproximação para \(\sigma^2\), ou seja, variância populacional. Assim:
possui distribuição \(\chi ^{2}\) se \(X\) possui distribuição normal.
Para \(n\) grande podemos aproximar a \(\chi ^{2}\) por uma distribuição normal. Olhe os gráficos de variância amostrais acima. Observe que para n=15 a distribuição de \(Var(X_i)\) é assimétrica e parece uma \(\chi ^{2}\), com o aumento da amostra vamos caminhando para uma distribuição normal.
10.3.3 Distribuição amostral da proporção
Considere uma amostra \(X_1, X_2, ..., X_{n}\) que assume os valores:
\(x_i=1\): sucesso
\(x_i=0\): fracasso
para \(i=1,2...,n\).
Seja \(p\) a probabilidade de sucesso. Então a proporção amostral pode ser calculada como:
\[\hat{p}= \frac{\sum_{i=1}^{n} X_i}{n}\]
Seja \(Y=\sum_{i=1}^{n} X_i\). Então \(Y\) possui distribuição Binomial com parâmetros \(E(Y)=n.p\) e \(Var(Y)=np(1-p)\).
Então, as caracteriticas da proporção, \(\hat{p}\), será :
\[E(\hat{p})= \frac{n p}{n} = p\]
\[Var(\hat{p})= \frac{1}{n^{2}} n p (1-p)= \frac{p(1-p)}{n}\]
Para n grande a distribuição de \(\hat{p}\) é aproximadamente Normal (pela aproximação da binomial pela Normal).