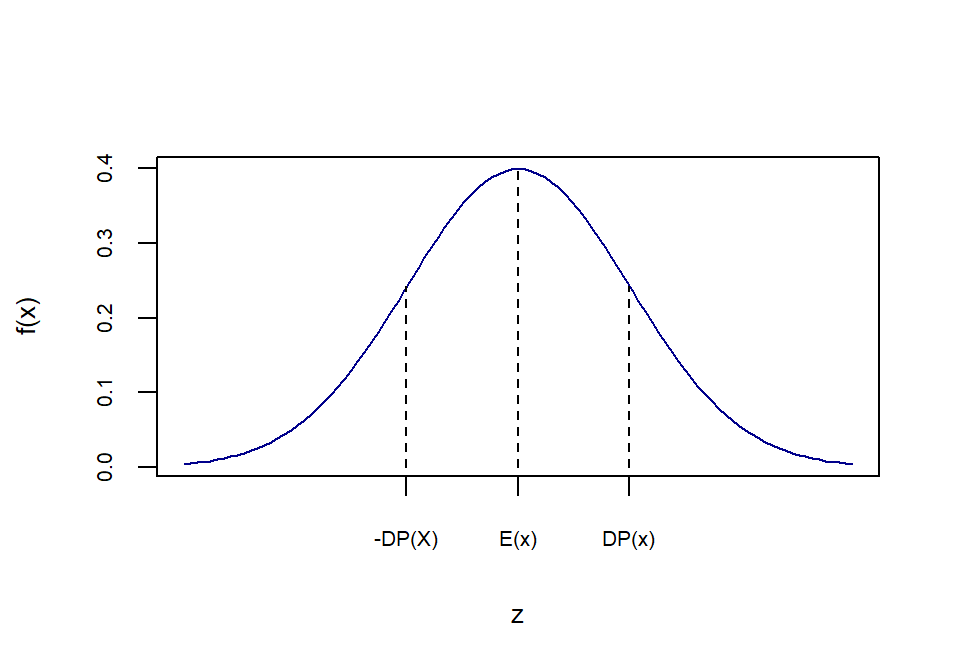
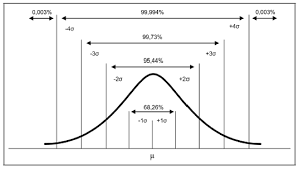
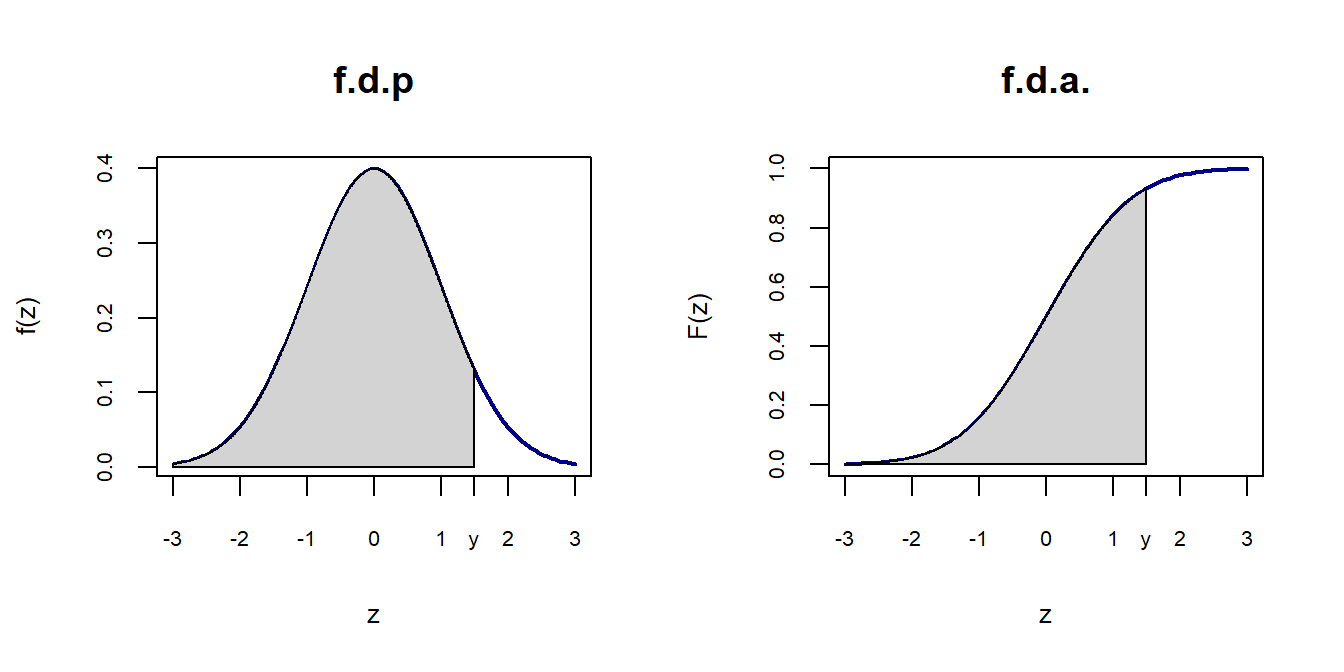
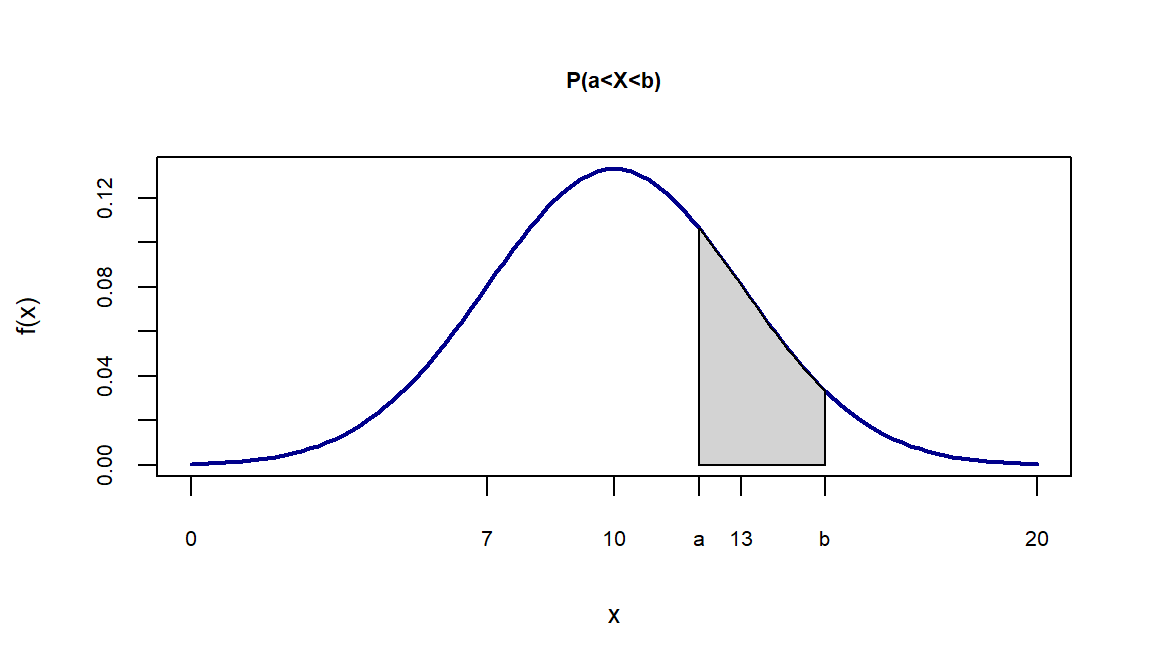
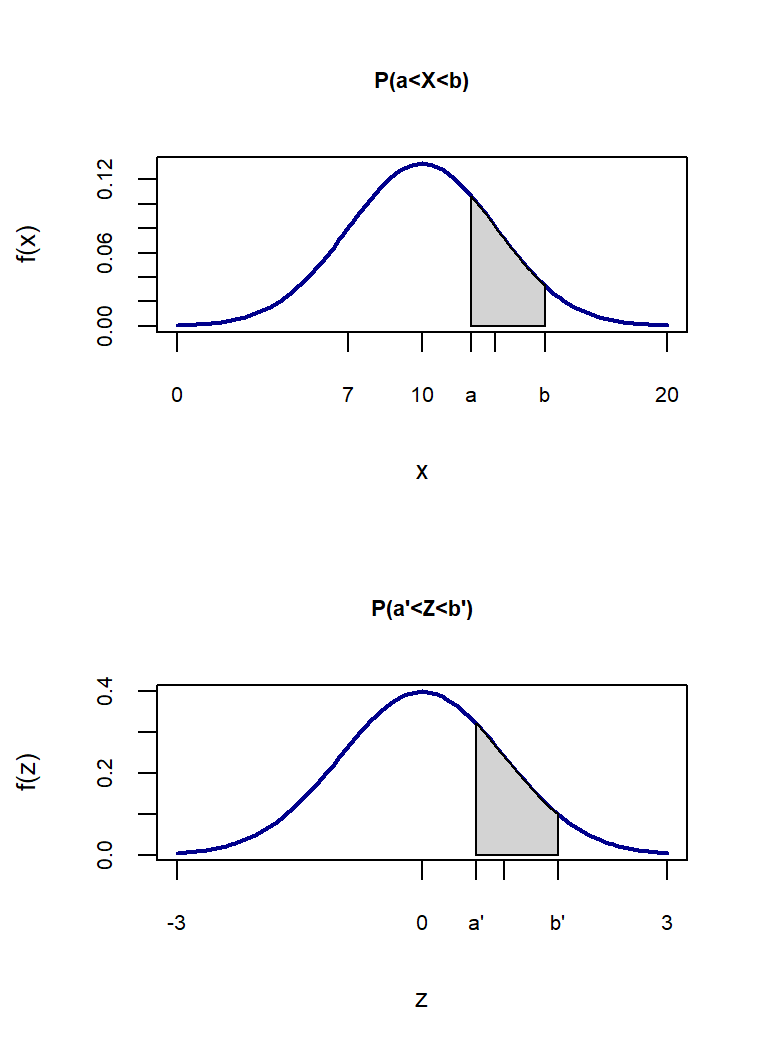
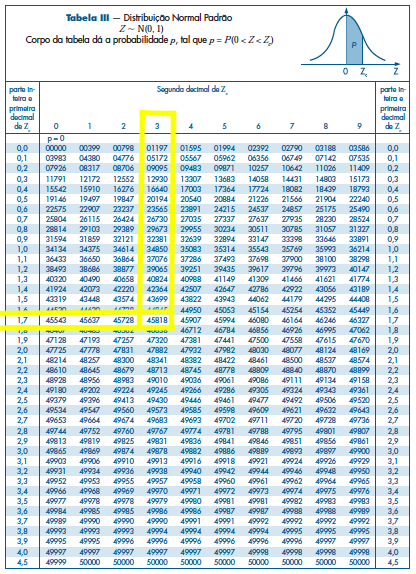
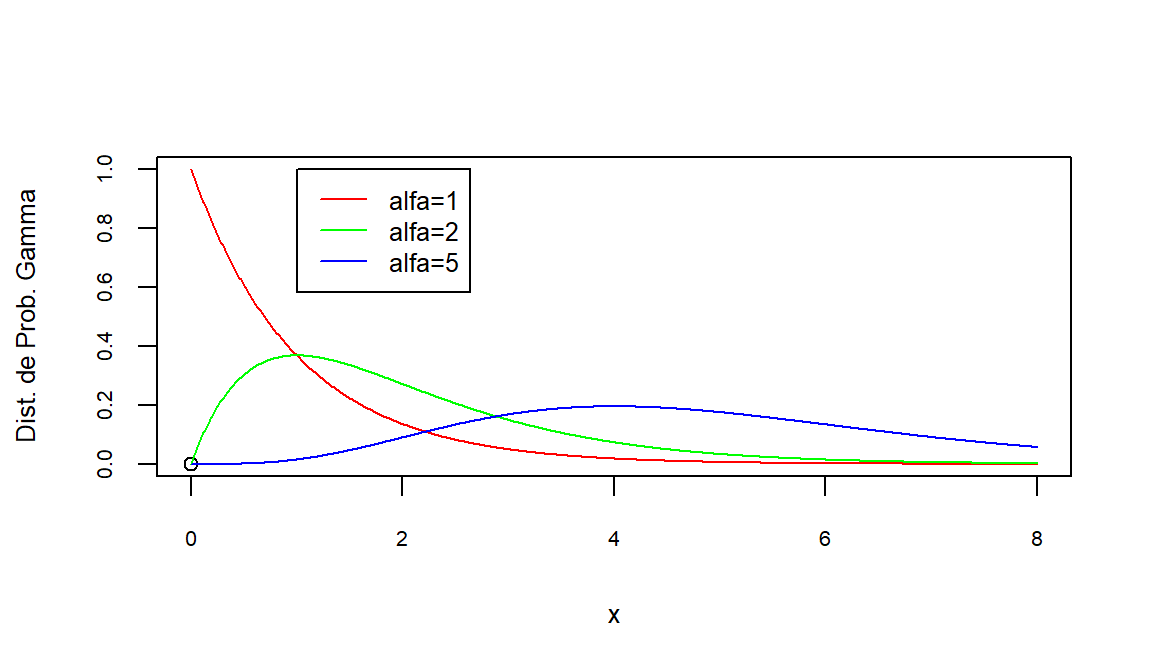
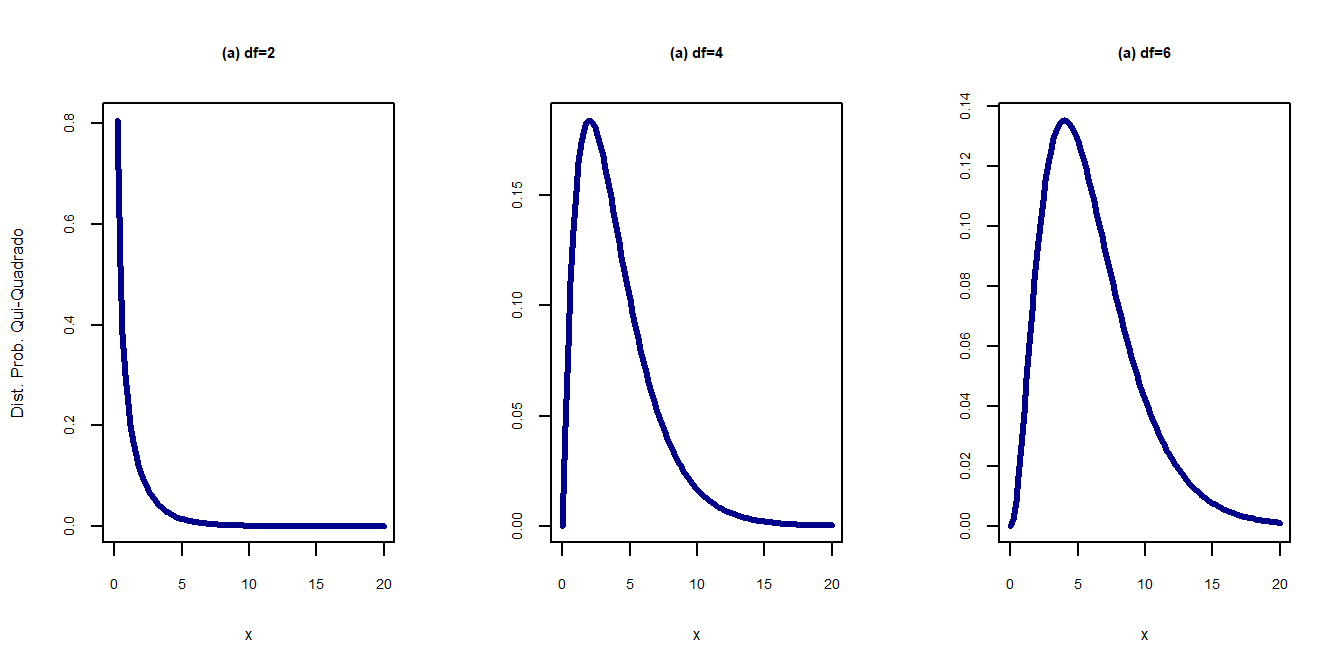
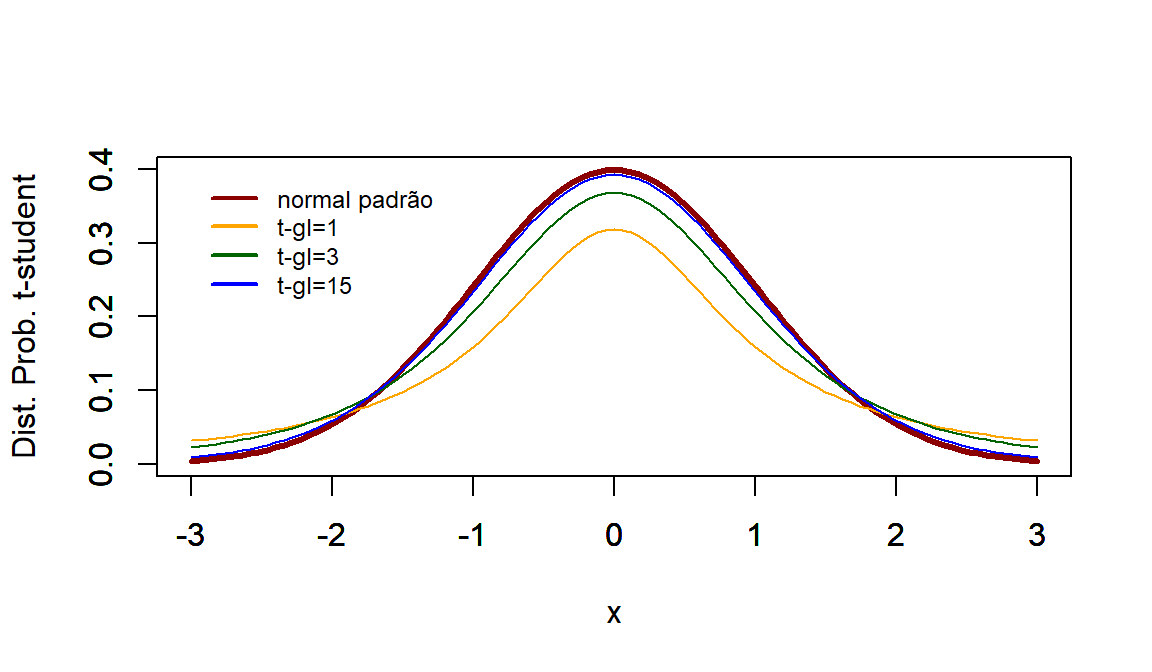
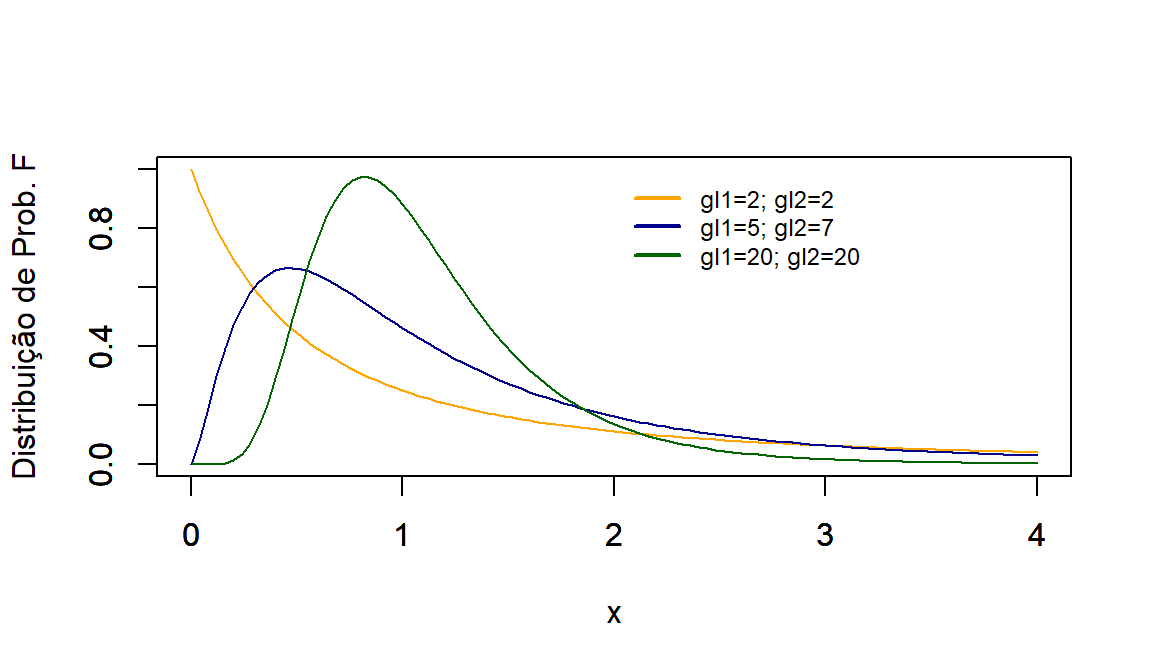
par(mfrow=c(2,1))
x<-seq(0,20,0.1)
fdnorm<-dnorm(x = x, mean = 10, sd=3)
regiao=seq(12,15,0.1)
cord.x <- c(min(regiao),regiao,max(regiao))
cord.y <- c(0,dnorm(regiao, mean=10, sd=3),0)
curve(dnorm(x,10,3),xlim=c(0,20),xlab="x",type="l",
col="darkblue",lwd=2, ylab="f(x)",xaxt="n",main="P(a<X<b)",
cex.axis=0.65, cex.lab=0.8, cex.main=0.7 )
axis(1,at=c(0,7, 10, 12,13, 15,20),labels =
c(0, 7, 10, "a",13,"b",20),cex.axis=0.65, cex.lab=0.8)
polygon(cord.x, cord.y, col='lightgray')
z<-seq(-3,3,0.1)
fdnorm<-dnorm(x = x, mean = 0, sd=1)
regiao=seq(0.66,1.66,0.1)
cord.x <- c(min(regiao),regiao,max(regiao))
cord.y <- c(0,dnorm(regiao, mean=0, sd=1),0)
curve(dnorm(x,0,1),xlim=c(-3,3),xlab="z",type="l",
col="darkblue",lwd=2, ylab="f(z)",xaxt="n",main="P(a'<Z<b')",
cex.axis=0.65, cex.lab=0.8, cex.main=0.7 )
axis(1,at=c(-3,1, 0, 0.66 ,1, 1.66, 3),labels =
c(-3, 1, 0, "a'",1,"b'",3),cex.axis=0.65, cex.lab=0.8)
polygon(cord.x, cord.y, col='lightgray')