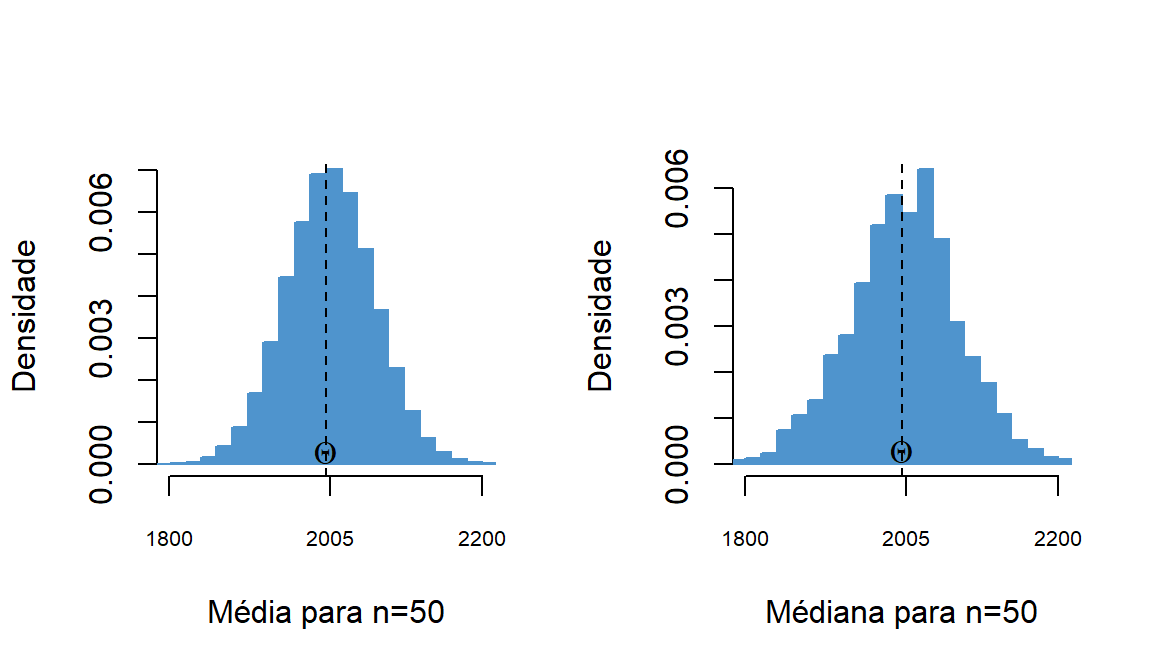
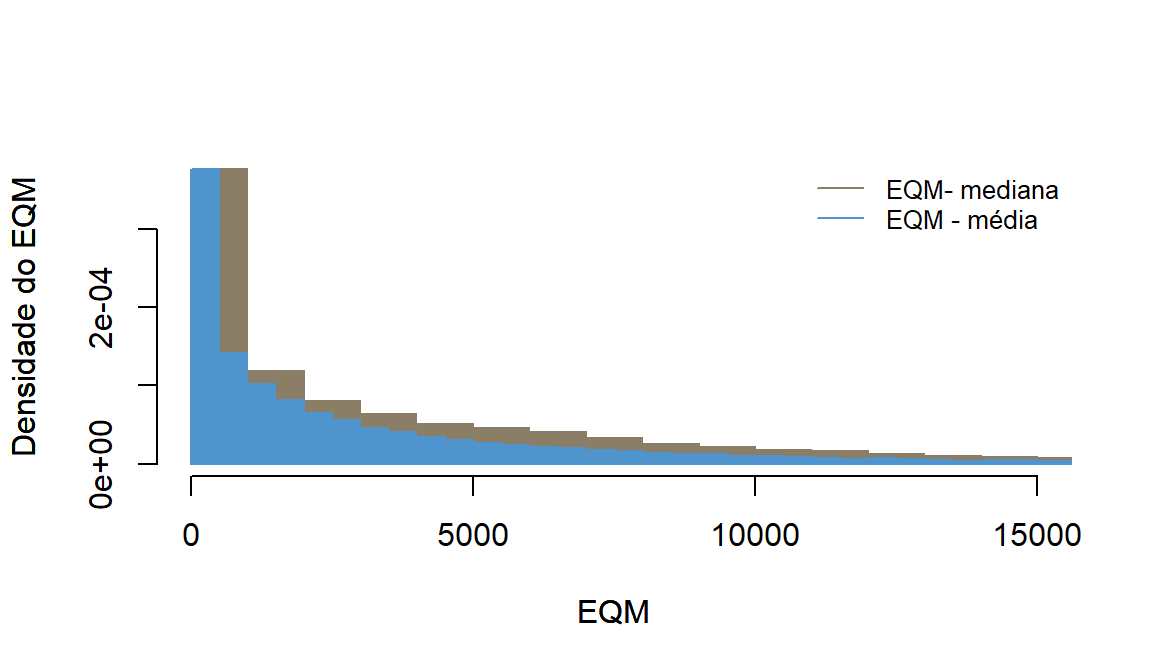
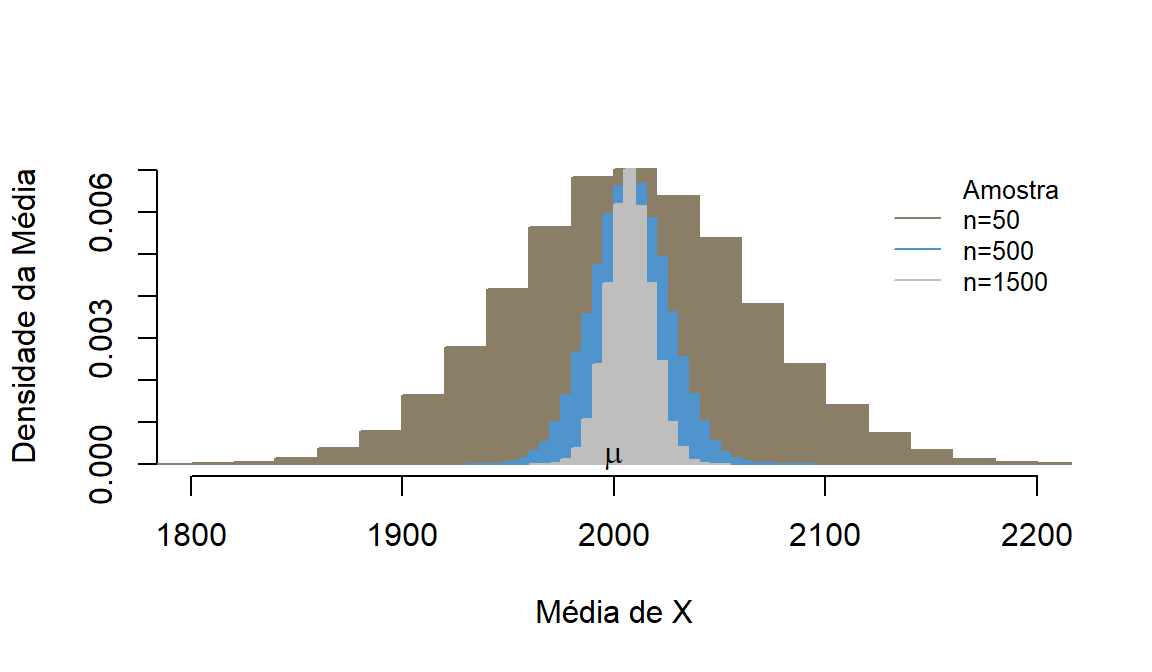
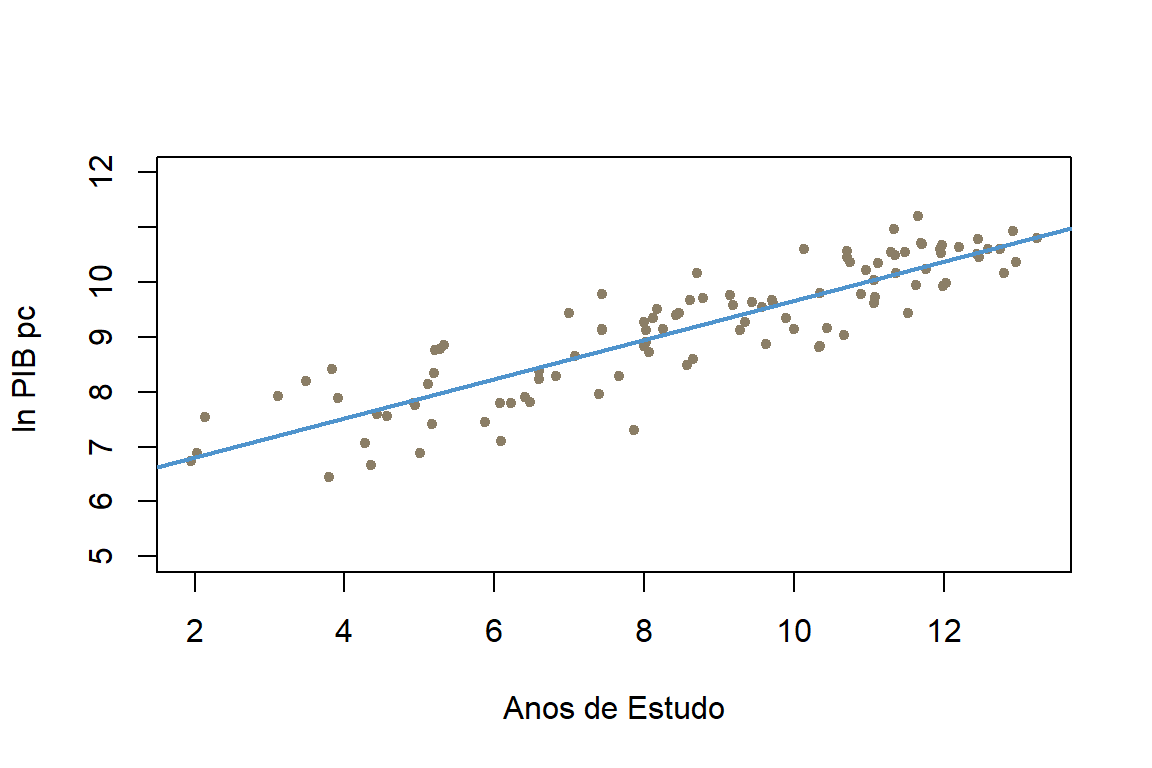
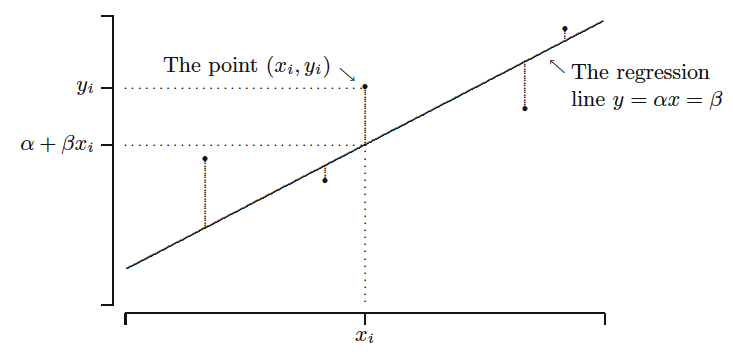
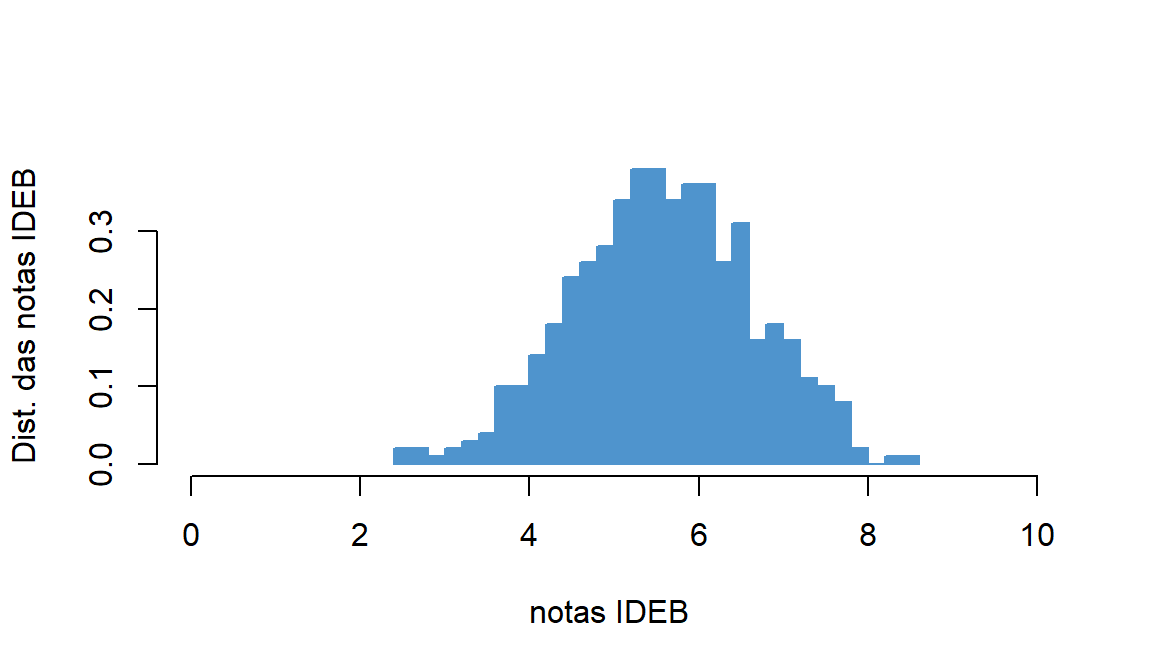
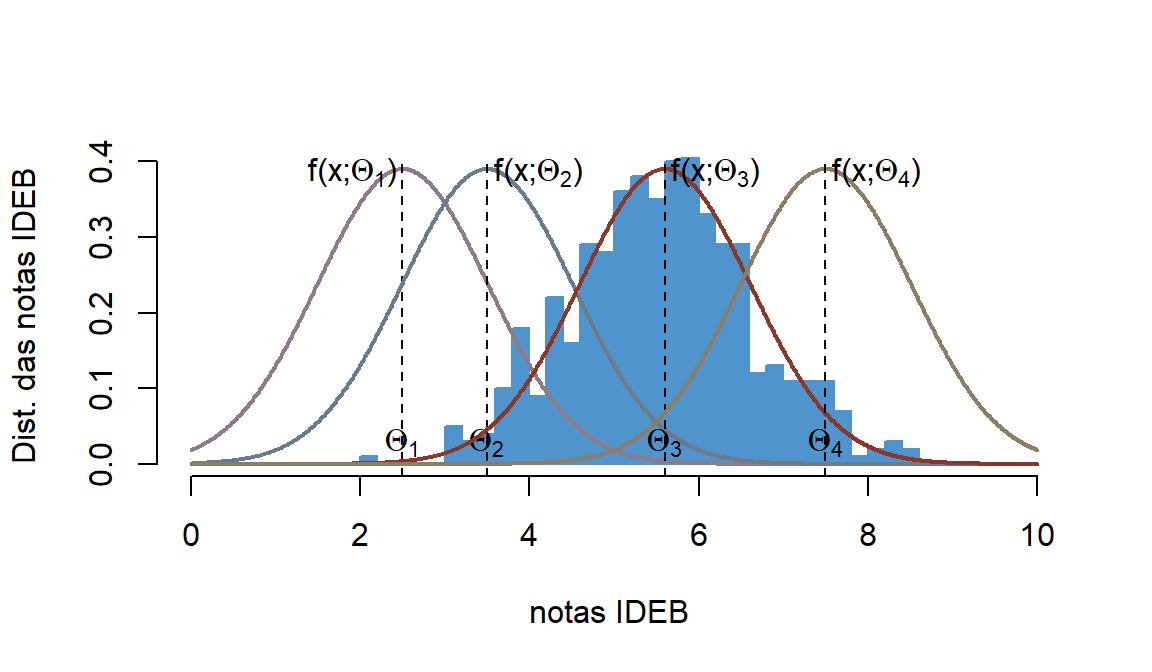
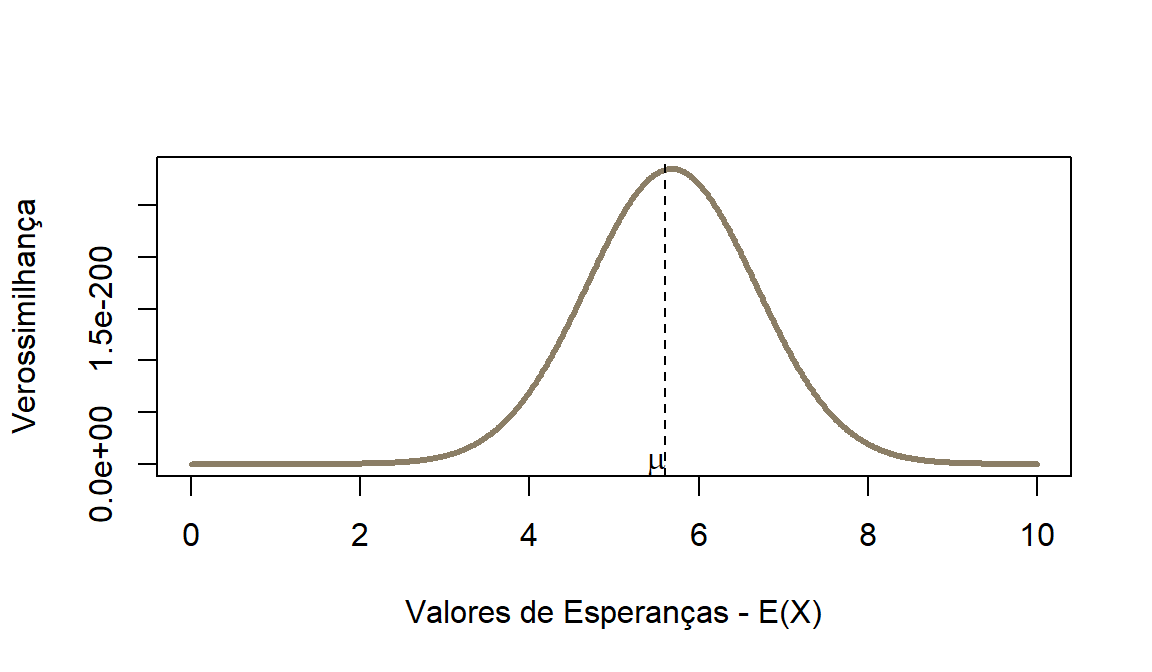
#Pib per capita em ln e anos de estudos de diversos países em 2010
ln_salario<- c(9.16, 9.44, 9.67, 10.71, 10.61, 7.79, 9.55, 10.55, 8.87, 7.56,
8.48, 9.51, 9.61, 7.75, 7.90, 10.60, 9.80, 9.14, 9.27, 9.40,
7.80, 10.24, 10.17, 6.45, 10.68, 9.35, 9.12, 9.12, 8.72, 8.84, 10.56, 10.49, 7.89, 10.61, 8.28, 10.16, 8.76, 7.41, 8.24, 10.64,
9.93, 10.54, 8.38, 8.90, 9.76, 9.14, 10.78, 10.46, 8.81, 10.51,
9.14, 7.82, 7.80, 6.67, 10.97, 6.88, 9.79, 7.54, 10.04, 9.63,
9.58, 8.77, 6.88, 8.14, 7.60, 10.69, 10.34, 8.29, 6.74, 11.20,
8.34, 9.62, 8.83, 9.13, 8.59, 9.95, 10.16, 9.73, 9.99, 7.92,
9.43, 7.06, 9.34, 10.36, 10.36, 9.03, 8.19, 8.86, 10.61, 10.93,
8.65, 10.52, 9.43, 7.11, 10.22, 9.27, 9.79, 7.45, 10.46, 10.81,
9.67, 9.70, 8.42, 7.96, 7.30)
educa<- c(10.44, 7, 9.71, 11.69, 10.13, 6.22, 9.57, 11.29, 9.63, 4.57, 8.57,
8.17, 11.07, 4.94, 6.41, 12.74, 10.35, 8.25, 9.35, 8.43, 4.93, 11.76,
12.8, 3.79, 11.97, 8.12, 8.02, 7.44, 8.06, 10.35, 10.71, 11.34, 3.92,
12.58, 7.66, 11.36, 5.21, 5.17, 6.6, 12.2, 11.98, 11.48, 6.59, 8.02,
9.15, 7.43, 12.45, 10.71, 10.33, 12.44, 10, 6.47, 6.08, 4.35, 11.33,
5.01, 10.89, 2.14, 11.06, 9.44, 9.18, 5.27, 2.03, 5.11, 4.44, 11.71,
11.12, 6.82, 1.95, 11.65, 5.19, 9.72, 7.99, 9.28, 8.65, 11.62, 8.71,
11.08, 12.02, 3.11, 11.52, 4.28, 9.89, 12.96, 10.75, 10.67, 3.49,
5.33, 11.95, 12.92, 7.07, 11.96, 8.47, 6.09, 10.96, 8, 7.44, 5.87,
12.46, 13.24, 8.61, 8.78, 3.84, 7.4, 7.86)
bd = data.frame(ln_salario, educa)
plot(bd$educa, bd$ln_salario, xlab="Anos de Estudo",
ylab="ln PIB pc ", pch=20, col="wheat4",ylim=c(5,12))
abline(lm(bd$ln_salario~bd$educa), col="steelblue3", lwd = 2)