Vamos separar em dois grupos de testes. Os testes sobre os parâmetros locacionais e os testes sobre probabilidades. Apesar do procedimento ser sempre aquele apresentado acima, existe mudanças na estatística que iremos utilizar dado a situação em questão.
16.1.1 Testes paramétricos para parâmetros locacional
16.1.1.1 Testes sobre Esperança de uma população com variância conhecida
Esse é nosso primeiro teste sobre a esperança populacional, \(\mu\) e ele parte do pressuposto que conhecemos a variância populacional, ou seja, \(\sigma^2=\sigma_0^2\). Vamos seguir os passos que mostramos anteriormente e construir o que seria a forma geral de testar uma hipótese neste caso;
1- Definindo a Hipótese
Podemos definir de forma Bicaudal ou Unicaudal
\[H_0: \mu=\mu_0\]\[H_1: \mu \neq \mu_0\]
ou
\[H_0: \mu=\mu_0\]\[H_1: \mu >\mu_0 \quad ou \quad H_1: \mu<\mu_0\]
2 - Definindo o Estimador
O estimador para a esperança já conhecemos, a média \((\bar{X})\). Para encontrar estimadores podemos utilizar uma das técnicas anteriores que vimos. \[\bar{X}=\frac{\sum_i{X_i}}{n}\] Sabemos que ao realizar um processo de amostragem aleatório, temos \(n\) medições de \(X\) (\(X_i\)) e cada uma dessas tem a mesma probabilidade de \(X\). Observamos \(x_i\). Dessa forma, considerando o TLC e a LGN tem-se: \[\bar{X}\sim N(\mu,\sigma^2/n)\]
Esse resultado é independente da distribuição de \(X\). Somente precisamos assumir normalidade de \(X\) para amostras pequenas, pois neste caso não conseguimos garantir as convergências em distribuição. Sob \(H_0\) temos o seguinte: \[\bar{X}\overset{H_0}{\sim} N(\mu_0,\sigma_0^2/n)\]
Logo o nosso Teste Estatístico \(T\), sob \(H_0\) será:
O controle do Erro Tipo I ou o nível de significância é uma escolha do pesquisador. Em economia utilizamos 10%, 5% e 1%. Com base na sua escolha podemos estabelecer as regiões críticas para o teste. Para: \[H_0: \mu=\mu_0\]\[H_1: \mu \neq \mu_0\]
Calcular o valor do teste estatístico com base na amostra retirada da população sob estudo. Agora teremos uma realização da média amostral das diversas possibilidades fornecidas pela distribuição de \(\bar{X}\). Tem-se: \[\bar{x}=\frac{\sum_i{x_i}}{n}\] Logo o valor do nosso teste estatístico será:
\[t=\frac{\bar{x}-\mu_0}{\sigma_0/\sqrt{n}}\]
Agora podemos comparar esse valor obtido com os valores ditos mais prováveis de ocorrerem sob \(H_0\). Basicamente faremos isso comparando o valor obtido, \(t\) com a nossa região crítica.
5 - Teste de hipótese
Assim se a nossa estimativa \(t\) pertencer a regiao crítica rejeitamos \(H_0\), ou seja, há evidências de que a afirmativa esteja errada. Caso não esteja na RC não rejeitamos \(H_0\) e portanto temos evidência de que esteja correto.
Vejamos agora um exemplo.
TipEXEMPLO
Suponha que temos uma máquina de empacotar que tem uma regulagem original com \(\mu=500\) e \(\sigma^{2}=400\). O gerente de qualidade da empresa mensalmente faz a aferição para verificar se a máquina está desregulada. Ele coleta aleatóriamente \(n=16\) pacotes e obteve a média \(\bar{x}=492\). O gerente deve parar a produção e chamar a equipe de manutenção ao nível de 1% de significância?
Resolvendo:
1 - Definindo a hipótese
Vamos adotar como hipótese nula a afirmação de que a máquina não desregulou. A hipótese alternativa é que a máquina pode ter desregulado para cima ou para baixo.
\[H_0: \mu=500 g\]\[H_{1}: \mu \neq 500 g\] Nesse caso utilizamos a hipótese bilateral.
2 - Definindo o Estimador
O estimador de \(\mu\) é a média \(\bar{X}\):
\[\bar{X}=\frac{\sum_iX_i}{16}\]
Sendo a distribuição desse estimador:
\[\bar{X}\sim N(\mu,\sigma^2/16)\]
Sob \(H_0\) temos a seguinte definição:
\[\bar{X}\overset{H_0}{\sim} N(500,400/16)\]
Logo o nosso Teste Estatístico \(T\), que nesse caso é a normal padronizada, sob \(H_0\) será :
Com base nas 16 elementos amostrados de \(X\), obtivemos:
\[\bar{x}=\frac{\sum_i{x_i}}{16}=492\]
Logo o valor do nosso teste estatístico será:
\[t=\frac{492-500}{20/4}=\frac{-8}{5}=1.6\]
Agora podemos comparar esse valor obtido com os valores ditos mais prováveis de ocorrerem sob \(H_0\). Basicamente faremos isso comparando o valor obtido, \(t\) com a nossa região crítica.
5 - Teste de Hipótese
Com base no \(t\) calculado procedemos o teste de hipótese. Sadendo que a RC é:
Como \(t=1.6\) ele não pertence a região, logo não rejeitamos \(H_0\), não há evidências de que a máquina desregulou e o gerente não deveria parar a produção para fazer a manutenção.
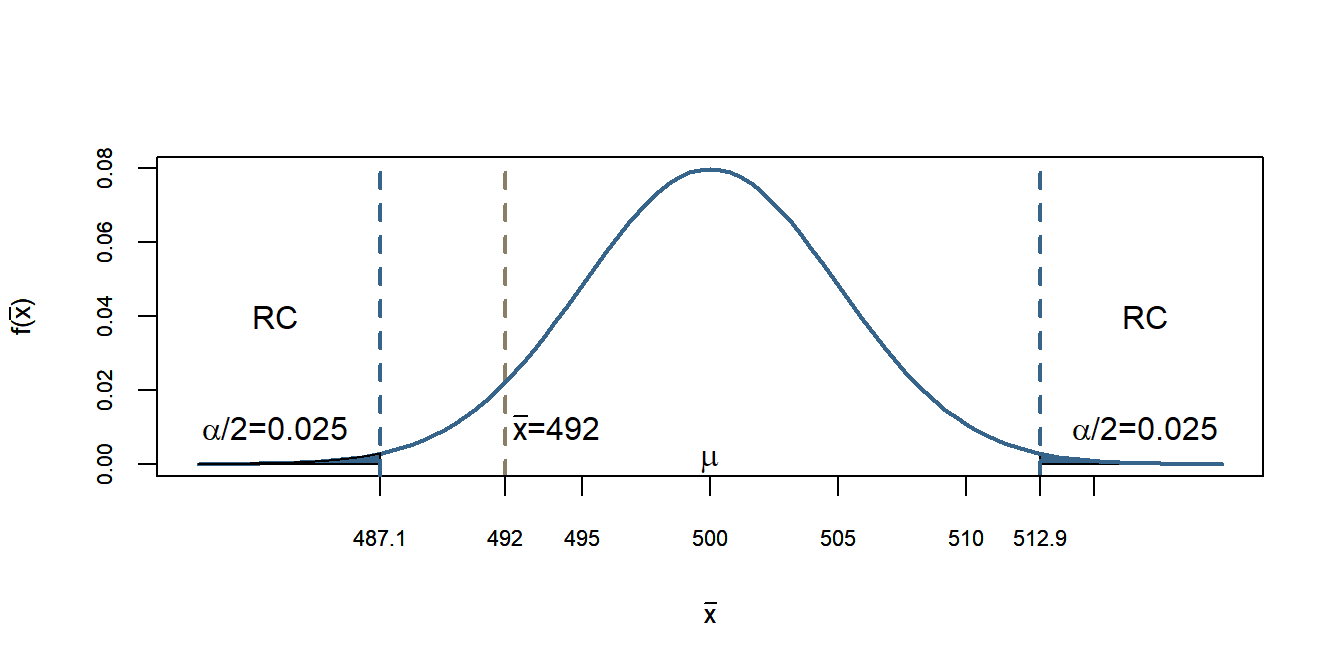
Uma outra maneira de fazermos é ao invés de utilizarmos a normal padronizada, encontrarmos quais são os limites da região crítica na distribuição de \(\bar{X}\). Assim poderemos fazer para o nível de significância, \(\alpha\) de 1%:
\[z_{c_1}=-2,58=(\overline{x}_{c1}-500)/5=487,1\]
\[z_{c_2}=2,58=(\overline{x}_{c2}-500)/5=512,9\]
Logo a região crítica análoga na distribuição de \(\bar{X}\) será:
Observamos na distribuição de \(\bar{X}\), a qual foi construída considerando \(H_0\) verdadeira, os valores críticos 487.1 e 512.9, bem como as regiões críticas. Nota-se que o valor de \(\bar{x}\) não está dentro da RC e portanto, não rejeitamos \(H_0\).
16.1.1.2 Utilizando a Probabilidade de Cauda ou Probilidade de Significância ou p-valor
Para fixarmos a ideia de p-valor, vamos fazer agora um teste de hipótese considerando apenas a probabilidade de cauda, ou probabilidade de significância ou o p-valor. O nome mais comum é p-valor. Agora não construiremos mais a região crítica e iremos calcular com base na estatística:
\[P(T\geq t_0|H_0)=p-valor=\hat{\alpha}\]
Vejamos um exemplo:
TipEXEMPLO
Uma empresa de transporte intermunicipal que ganhou uma concessão do Estado afirma que o tempo de viagem, \(X\), entre duas cidades de acordo com seus estudos preliminares pode ser assim descrito:
\[X \sim N (300,30^{2})\]
Inclusive esse tempo foi um dos critérios utilizados no processo de cessão. O Ministério Público desconfia e acredita que esse valor é maior. O MP faz um estudo considerando 10 viagens aleatórias e encontra que \(\overline{x}=314\). O MP deve se reunir com a empresa e pedir um ajustamento de conduta?
Resolvendo:
1 - Definindo a hipótese
\[H_0: \mu=300\]
\[H_1: \mu\geq 300\]
2 - Definindo o Estimador
Sabemos que \(\bar{X}\) será:
\[\overline{X} \sim N (\mu; \sigma^{2}/10 )\]
e considerando que a empresa está correta, ou seja, sob \(H_0\):
\[\overline{X} \sim N (300; 900/10)\]
3 - Nivel de Significância e Região Crítica
Não precisamos mais calcular!!
4 - Cálculo do Teste Estatístico
Com \(\bar{x}_0=314\) e sob \(H_0\), calculamos a probabilidade de ocorrência de amostras com o valor iguais ou superiores a \(\overline{x}=314\):
Caso fosse bicaudal e sabendo que a distribuição é simétrica poderiamos considerar:
\[\hat{\alpha}=14\%\]
5 - Teste de Hipótese
Considerando o teste unilateral, temos agora a força da rejeição. A chance de retirarmos 314 ou mais é de 7%. Apesar de baixo poderia ocorrer. Não parece muito improvável, tanto que se considerarmos \(\alpha=1\%\) ou \(\alpha=5\%\) não rejeitamos. Só rejeitariamos \(H_0\) se \(\alpha=10\%\). Podemos concluir que as evidências não nos revelam que a empresa está tendo um tempo maior de viagem, apesar dessa conclusão não ser tão forte.
16.1.2 Teste sobre a Esperança de uma população normal com variância desconhecida
O procedimento aqui é análogo ao que fizemos anteriormente para testar a média quando conheciamos o desvio populacional \(\sigma\). Entretanto o nosso teste estatístico que era:
\[T=\frac{\bar{X}-\mu_0}{\sigma_0/\sqrt{n}}\]
Não pode ser calculado pois não conhecemos mais \(\sigma_0\). Temos que substituir esse parâmetro pela sua estimativa.
\[S_X^2=\frac{1}{n-1}\sum_i (X-\bar{X})^2\]
Dessa forma, nosso novo teste estatístico será:
\[T=\frac{\bar{X}-\mu_0}{S_X/\sqrt{n}}\]
Nossa questão agora é qual a distruibuição desse teste? Agora tanto \(\bar{X}\) como \(S_X\) são variáveis aleatórias e possuem distriuição. Para verificar, vamos dividir o numerador e o denominador por uma constante - desvio, \(\sigma\)
E terá uma distribuição t-student com n-1 graus de liberdade. Agora nossa região crítica tem que ser construída com base na tabela da distribuição t.Para o caso bicaudal:
\[RC=\{t \in \mathbb{R} |t\leq - t_{c,\alpha/2} \quad ou \quad t\geq t_{c,\alpha/2}\}\] Para o caso unicaudal:
Um fabricante afirma que seus cigarros não contém mais do que 30mg de nicotina. O Ministério da Saúde está desconfiado dessa afirmativa e acredita que o conteúdo de nicotina é maior do que o anunciado (teste unilateral). Foi realizada uma amostra de 25 cigarros e o teor médio de nicotina nos mesmos foi \(\overline{x_0}=31,5mg\) e o desvio padrão amostral \(S_X=3mg\). Com \(\alpha=5\%\) os dados confirmam a informação?
1 - Definindo a hipótese
\[H_0: \mu=30\]
\[H_1: \mu\geq30\]
2 - Definindo o Estimador
O estimador de \(\mu\) é a média \(\bar{X}\):
\[\bar{X}=\frac{\sum_iX_i}{25}\]
Logo o nosso Teste Estatístico \(T\), que nesse caso é a padronização de \(\bar{X}\) e considerando o estimador da variância será, sob \(H_0\):
Todos os valores da estatística acima de 1,711 fazem parte da nossa região crítica.
4 - Cálculo do Teste Estatístico
Foram amostrado 25 elementos de \(X\), obtivemos:
\[\bar{x}=\frac{\sum_i{x_i}}{25}=31.5\]
Logo o valor do nosso teste estatístico será:
\[t=\frac{31.5-30}{3/5}=\frac{1.5}{0.6}=2.5\]
Agora podemos comparar o valor obtido, \(t\) com a nossa região crítica.
5 - Teste de Hipótese
Nosso teste foi \(T=2.5\) e nossa região crítica \(RC=\{t\geq 1,711 \}\). Logo pertence à região crítica. Dessa forma, rejeitamos \(H_0\) mostrando que há evidências de que o teor de nicotina é maior do que o anunciado pela firma.
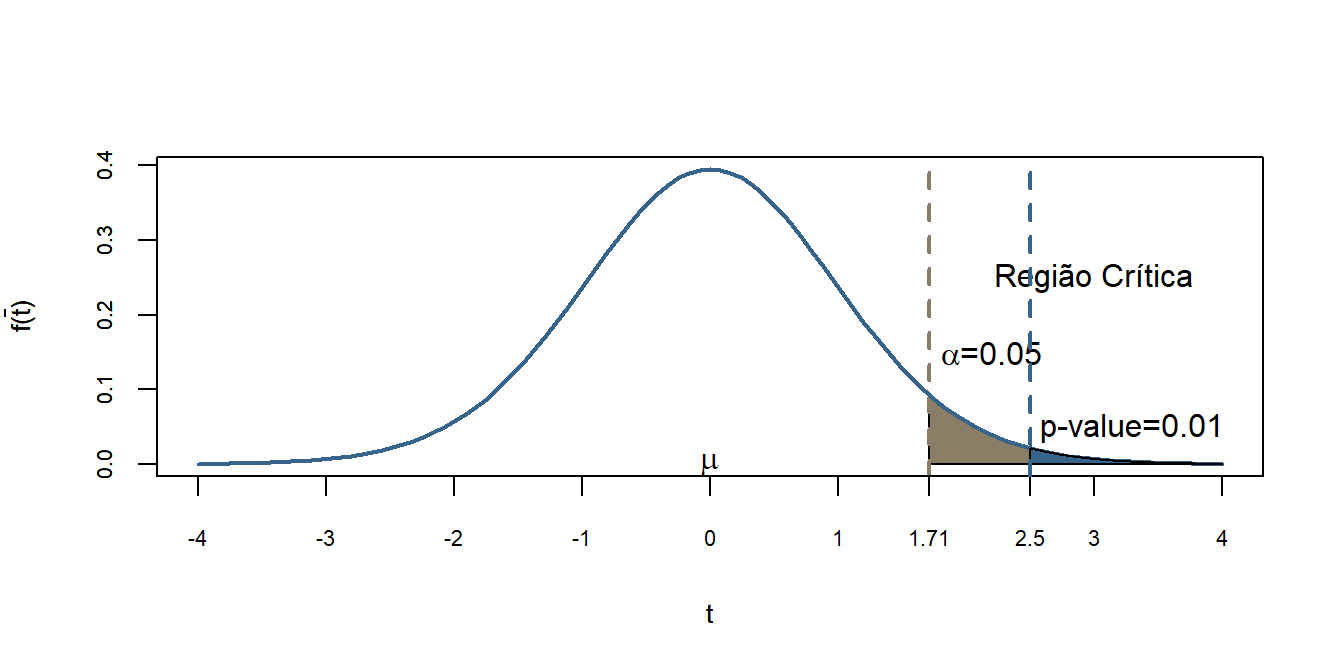
6 - Extra 1: Probabilidade de cauda ou p-valor
Vamos ver qual a probabilidade de encontrarmos os valores \(T=2.5\) ou maiores em uma amostra que veio de uma população sob \(H_0\) ou seja, \(\mu=30g\).
o que também leva à rejeição de \(H_0\) ao nível de 5% de confiança.
7 - Extra 2: O Intervalo e Confiança
Como rejeitamos, poderiamos estar interessados em descobrir onde estaria a verdadeira média populacional ao nível de 5% de confiança. Vamos calcular o intervalo de confiança para 5% ( \(t_\gamma=2,064\)):
\[\begin{array}{ccc}
I C(\mu ; 0.95)=31,5 \pm(2.064) 3/\sqrt{25}
\\
\\
I C(\mu ; 0.95)=\{30.26 ; 32.74\}
\\
\\
\end{array}\]
Logo o verdadeiro parâmetro populacional \(\mu\) estaria entre \(30.26\) e \(32.74\).
8 - Extra 3: Simulando o nosso problema
Vamos agora simular a distribuição t-student sob \(H_0\) e verificar o valor obitido, a RC e o p-valor
Nível de significância e p-valor para distribuição t-student
16.1.3 Comparação de duas populações normais: amostra independente
Nesse caso não quero mais saber se a esperança de uma população é igual a um determinado valor \(H_0:\mu=k\) agora queremos saber se uma população possui o mesmo valor de esperança que a outra população. Por exemplo se a renda per capita é da cidade é igual a renda per capita no campo. Agora comparamos duas médias \(H_0:\mu_1=\mu_2\). Aqui assumimos que elas são normais e as amostras são independentes:
\[P_1 \sim N(\mu_1,\sigma^2_1)\]
\[P_2 \sim N(\mu_2,\sigma^2_2)\]
1 - Definindo a hipótese
\[H_0: \mu_1=\mu_2\]
\[H_1: \mu_1\neq\mu_2\]
2 - Definindo o Estimador
Supondo que retiramos uma amostra de \(n\) elementos da população 1 \(X\) e de \(m\) elementos da população 2, \(Y\). Sob \(H_0\) temos:
Dessa forma construímos nossa região crítica com base nos valores críticos determinados pelo nosso nível de significância (\(\alpha\)) na normal padrão \((\phi)\), ou seja, \(z_{c,\alpha}\)
2.2 - Caso 2: Para variância desconhecida e iguais
No teste de igualdade de variância essa não foi rejeitada. Temos que \(S_1^2\) e \(S_2^2\) são dois estimadores não viesados de \(\sigma^2\). Novamente retiramos uma amostra de \(n\) elementos da população 1 \(X\) e de \(m\) elementos da população 2, \(Y\). Assim:
Dessa forma construímos nossa região crítica com base nos valores críticos determinados pelo nosso nível de significância (\(\alpha\)) na t-student \(t(n+m-2))\), ou seja, \(t_{\alpha,(n+m-2)}\)
Novamente, nossa região crítica é elaborada com base nos valores críticos determinados pelo nosso nível de significância (\(\alpha\)) na t-student \(t(v)\), ou seja, \(t_{\alpha,(v)}\)
Vejamos agora dois exemplos. O primeiro é para as variâncias conhecidas e o segundo para variâncias desconhecidas mas iguais!
TipEXEMPLO
Teste de diferença de médias com variâncias conhecidas
Uma empresa propos um novo sistema de monitoramento de processo e quer verificar se esse faz com que os funcionarios tenham melhor performance. Foi feito um ensaio com 8 funcionários sob o monitoramento atual \((X)\) e a performance média registrada foi de 80.5 pontos. Sabe-se que o desvio padrão populacional, \(\sigma_X=1.5\). Foi feito outro ensaio com 10 funcionários sob o novo monitoramento \((Y)\) e a performance foi de 81.3 pontos. Aqui também conhecemos o desvio padrão populacional, \(\sigma_X=3.8\)
1 - Definindo a hipótese
Vamos adotar o teste unilateral pois sabemos que o novo processo pode performar igual ou melhor e não pior.
\[H_0: \mu_X=\mu_Y\]
\[H_1: \mu_X\leq\mu_Y\]
2 - Defindo o Estimador
Para variância conhecida e considerando a a hipótese nula utiliza-se o seguinte estimador:
Considerando o nível de 5% de significância e teste unilateral temos a seguinte região crítica para T, com base na tabela normal padrão, \(z_{c,0.05}\):
Como -0.61 não está na região crítica, não rejeitamos a hipótese nula de que os dois processos de monitoramento produzem o mesmo resultado. Isso indica que se houver algum custo adicional na implementação do monitoramento 2, esse será um prejuízo para a empresa.
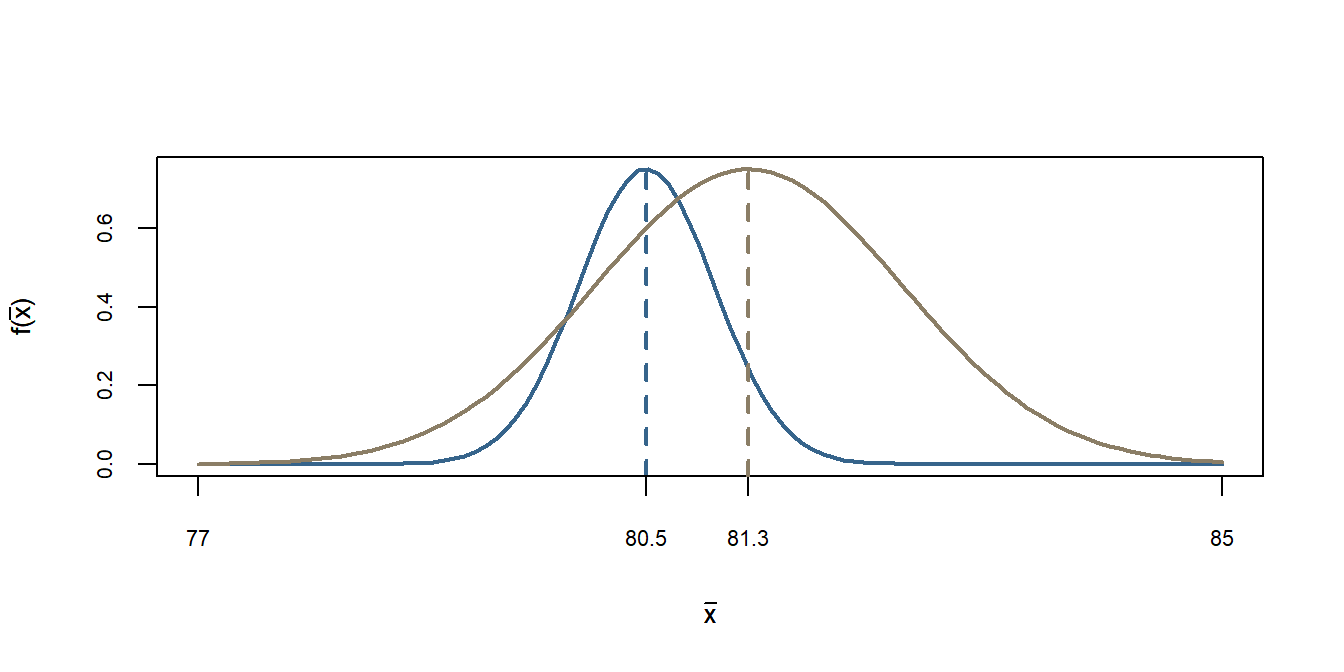
6 - Simulando as duas distribuições
Veja nas simulações como as duas distribuições estão próxima uma da outra indicando que não conseguimos diferenciar. Isso é a explicação visual do porque não houve diferença entre as médias dos dois monitoramentos.
Simulando as duas distribuições do monitoramento, supondo normalidade
TipEXEMPLO
Teste de diferença de médias com variâncias desconhecidas e iguais
Uma empresa está testando duas misturas de concretos os quais são feitos com cimento de diferentes minas. A mistura 1 é a mistura padrão feita com o cimento já conhecido. A mistura 2 usa a mesma receita mas utiliza um cimento vindo de uma nova mina. A empresa quer saber se as duas misturas produzem a mesma qualidade de produto, ou seja, que a carga de ruptura do concreto após 28 dias é a mesma em \(kg/cm^2\). A tabela abaixo traz os testes laboratoriais e gostariamos de saber se ao nível de 5% de confiança as duas misturas possuem a mesma esperança?
Resolvendo:
Considerando que \(X\) é a carga de ruptura da mistura 1 \((x_1, x_2, ...., x_{12})\) e que \(Y\) é a carga de ruptura da mistura 2 \((y_1, y_2, ...,y_{10})\). Vamos calcular as médias e desvio padrões amostrais:
Para variância desconhecida e iguais e assumindo que ambas as populações possuem distribuição normal. Sob a hipótese nula utiliza-se utiliza-se o seguinte estimador:
Considerando o nível de 5% de significância e teste bilateral temos a seguinte região crítica para T, com base na tabela t-student, \(t_{(12+10-2)}=t_{(20)}\)
Como 2.84 está na região crítica rejeitamos a hipótese de que as duas misturas produzem concretos com a mesma carga de ruptura, indicando que há evidências de que a carga de ruptura da nova mistura 2 é menor do que a mistura original.
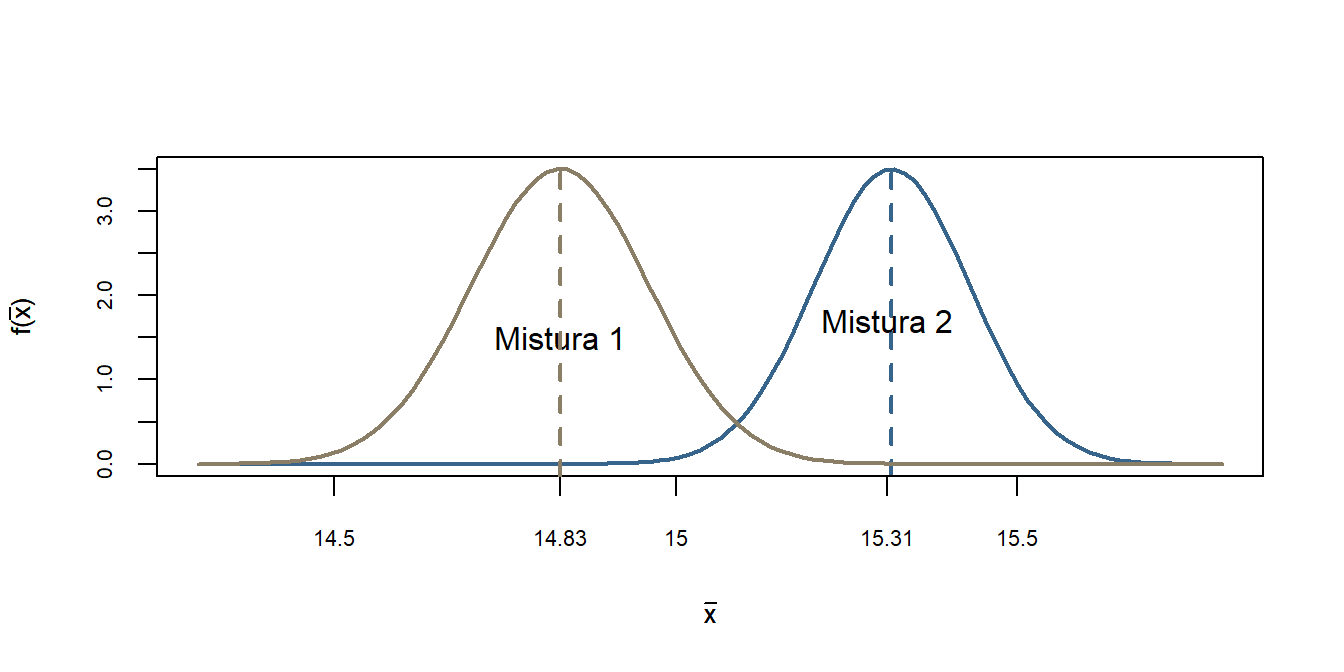
6 - Extra: Simulando as duas distribuições
Podemos observar as duas distribuições da média para a mistura 1 e para a mistura 2. Observa-se que elas estão distantes uma da outra indicando visualmente que elas vem de populações distintas.
Simulando as duas distribuições do monitoramento, supondo normalidade.
16.1.4 Testes Paramétricos sobre Probabilidades
16.1.4.1 Teste para proporção
Aqui estamos interessados em eventos que podem ocorrer (1) e que não podem ocorrer (0), tratados em geral por uma distribuição Binomial. Aqui podemos citar exemplos de pesquisas eleitorais, pessoas favoráveis a uma política, empresas que entraram em recuperação judicial, indiívuos que possuem dívida em atraso etc. Vamos trabalhar aqui com a estratégia de aproximação da binomial pela normal.
1- Definindo a Hipótese
Podemos definir de forma Bicaudal ou Unicaudal
\[H_0: p=p_0\]\[H_1: p \neq p_0\] ou
\[H_0: p=p_0\]\[H_1: p >p_0 \quad ou \quad H_1: p<p_0\]
2 - Definindo o Estimador
O estimador para a proporção seria \(\hat{p}=\frac{\sum_i{X_i}}{n}\). Para encontrar o teste estatístico utilizaremos a ideia de aproximação da binomial pela normal.
Sabemos pelo que vimos anteriormente que ao realizar um processo de amostragem aleatório, temos \(n\) medições de \(X\) (\(X_i\)) e cada uma com a mesma distribuição de \(X\) - binomial. Observamos \(x_i\). Dessa forma, considerando o TLC e a LGN tem-se:
\(\mu=np\) e que \(\sigma^2=np(1-p)\). Para um \(n\) suficientemente grande,\(X \sim b(n,p)\) pode ser aproximado por \(N(np,np(1-p))\).
Como, \(\hat{p}=\frac{\sum_i{X_i}}{n}\), a distribuição da proporção amostral será \(\hat{p} \sim N(p,p(1-p)/n)\)
Portanto Sob \(H_0\) o nosso Teste Estatístico \(T\), será:
Calcular o valor do teste estatístico com base na amostra retirada da população sob estudo. Agora teremos uma realização da proporção amostral das diversas possibilidades fornecidas pela distribuição de \(\hat{p}\). Tem-se:
Comparamos o valor obtido, \(t\) com a nossa região crítica.
5 - Teste de hipótese
Assim se a nossa estimativa \(t\) pertencer a região crítica rejeitamos \(H_0\). Caso não esteja na RC não rejeitamos \(H_0\).
Vejamos agora um exemplo extraído de Bussab e Moretim:
TipEXEMPLO
Temos uma estação de TV que afirma que \(60\%\) das Tv’s estavam sintonizadas no seu programa as 20h. Uma emissora concorrente contesta essa afirmação dizendo que na verdade esse percentual é bem menor. Ela contrata uma empresa para verificar quem está com a razão, pois isso tem impactos diretos sobre a quantidade de propaganda que conseguem negociar. Essa empresa contratou você para realizar o teste. Já antecipando fez um processo de amostragem com 200 famílias e ao nível de significância de 5% quem teria razão? (teste unilateral)
Uma outra maneira de proceder seria utilizar a distribuição de \(\hat{p} \sim N(0.6; 0.24/200)\) sob \(H_0\) para encontrarmos o valor crítico e a região crítica na distribuição de \(\hat{p}\). Procedemos da seguinte maneira: