install.packages("ggsurvfit")
remotes::install_github("courtsbr/JurisMiner")17 Oficina sobre análise de sobrevivência
18 Oficina em análise de sobrevivência
18.1 Instalar pacotes
18.2 Criar um projeto
usethis::create_project("nome_do_seu_projeto")18.3 Criar pastas necessárias
dir.create("data-raw")
dir.create("data")
dir.create("docs")
dir.create("R")
dir.create("data-raw/datajud")18.4 Criar primeiro script
file.create("R/rotina_1_coleta.R")18.5 Carregar pacotes necessários
library(tidyverse)
library(janitor)
library(ggsurvfit)
library(datajud)
library(JurisMiner)18.6 Definir os parâmetros para coleta dos dados
tribunal <- "tjto"
classe <- "282" ## Dei exemplo do juri
grau <- "G1"
assunto <- ""
distribuicao <- "26"
julgado <- ""
data_inicial <- "2020-01-01"
data_final <- "2025-11-25"
tamanho_pagina <- 1000
diretorio <- "data-raw/datajud"18.7 Baixar os dados do datajud
set_api_key(get_default_api_key())
results <- search_processes_paginated(
tribunal = tribunal,
classe_codigo = classe,
grau = grau,
dataAjuizamento_start = data_inicial,
dataAjuizamento_end = data_final,
page_size = tamanho_pagina,
max_pages = NULL, # Buscar todas as páginas disponíveis
save_pages = TRUE, # Salvar cada página
output_dir = diretorio
)18.8 Ler arquivos
arquivos <- list.files(diretorio, full.names = TRUE)
juri <- map_dfr(arquivos, readRDS)18.9 Limpeza
juri <- juri |>
clean_names()
juri <- juri |>
mutate(data_ajuizamento = str_sub(data_ajuizamento, 1,8) |> ymd()) |>
mutate(data_atualizacao = str_sub(data_hora_ultima_atualizacao, 1,10) |> ymd(), .after = tribunal)
juri <- juri |>
slice_max(order_by = data_atualizacao, by = c(numero_processo), n = 1)18.10 Classe
classe <- juri |>
select(numero_processo, classe) |>
unnest_longer(classe) |>
mutate(classe = unlist(classe)) |>
distinct() |>
pivot_wider(names_from = "classe_id", values_from = "classe" )18.11 Órgão julgador
orgao_julgador <- juri |>
select(numero_processo, orgao_julgador) |>
unnest_longer(orgao_julgador) |>
mutate(orgao_julgador = unlist(orgao_julgador)) |>
distinct() |>
pivot_wider(names_from = "orgao_julgador_id", values_from = "orgao_julgador" ) |>
clean_names() |>
unnest(cols = c(codigo_municipio_ibge, codigo, nome))entrancias <- jsonlite::fromJSON("https://gist.githubusercontent.com/jjesusfilho/c150c20e5c1b45bf62d3057e78d86652/raw/99d21a002abb09d0f7b82f4241f9c25e8b0a29b9/entrancias_tjto.json")
entrancias <- entrancias |>
mutate(codigo = as.character(codigo)) |>
select(codigo, entrancia)
orgao_julgador <- orgao_julgador |>
left_join(entrancias, by = "codigo")18.12 Assuntos
assuntos <- juri |>
select(numero_processo, assuntos) |>
unnest_longer(assuntos) |>
unnest_wider(assuntos, names_sep = "_") |>
unnest_wider(assuntos_1)18.13 Movimentação
movimentacao <- juri |>
select(numero_processo, movimentos) |>
unnest_longer(movimentos) |>
unnest_wider(movimentos) |>
clean_names() |>
select(processo = numero_processo, codigo, nome, data_hora) |>
mutate(data_hora = ymd_hms(data_hora, tz = "America/Sao_Paulo")) |>
group_by(processo) |>
arrange(desc(data_hora)) |>
tempo_movimentacao(data_hora) |>
rename(numero_processo = processo)18.13.1 Seleção dos códigos de eventos de interesse
codigos_eventos <- c(10953, 10961,11877) # pronúncia, impronúncia e absolvição sumária
codigos_impeditivos <- c(1042,12769, 12735) ## Morte, desclassificação, extinção da punibilidade
codigos_todos <- c(codigos_eventos, codigos_impeditivos)
eventos <- movimentacao |>
filter(codigo %in% codigos_todos)
eventos <- eventos |>
mutate(evento = case_when(
codigo %in% codigos_eventos ~ "decidido",
TRUE ~ "impedido"
))
eventos <- eventos |>
select(numero_processo, tempo = decorrencia_acumulada, evento)18.13.2 Filtros dos casos censurados
nao_eventos <- movimentacao |>
anti_join(eventos, by = "numero_processo")
nao_eventos <- nao_eventos |>
group_by(numero_processo) |>
filter(decorrencia_acumulada == max(decorrencia_acumulada))
nao_eventos <- nao_eventos |>
mutate(evento = "censurado") |>
select(numero_processo, tempo = decorrencia_acumulada, evento)18.13.3 Junção dos dois
eventos <- eventos |>
bind_rows(nao_eventos)
eventos <- eventos |>
distinct()18.13.4 Filtrar assuntos
codigos_assuntos <- c(3372, 5555,3370, 12091, 11244) ## homicidio qualificado, simples, tentado e feminicidio.
assuntos_selecionados <- assuntos |>
filter(assuntos_codigo %in% codigos_assuntos)
assuntos_selecionados <- assuntos_selecionados |>
select(numero_processo, crime = assuntos_nome) |>
mutate(crime = JurisMiner::snakecase(crime)) |>
distinct(numero_processo, .keep_all = TRUE)18.14 Junta as duas tabelas
orgao_entrancia <- orgao_julgador |>
select(numero_processo, entrancia) |>
distinct()
base <- eventos |>
inner_join(assuntos_selecionados, by = "numero_processo") |>
inner_join(orgao_entrancia)Loading required package: ggplot2── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ lubridate 1.9.4 ✔ tibble 3.3.0
✔ purrr 1.2.0 ✔ tidyr 1.3.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors18.15 Curva de Kaplan Meier
survfit(Surv(tempo) ~ entrancia , data = base) |>
ggsurvfit(linewidth = 1) +
add_confidence_interval() +
add_risktable() +
add_quantile(y_value = 0.6, color = "gray50", linewidth = 0.75) +
scale_ggsurvfit()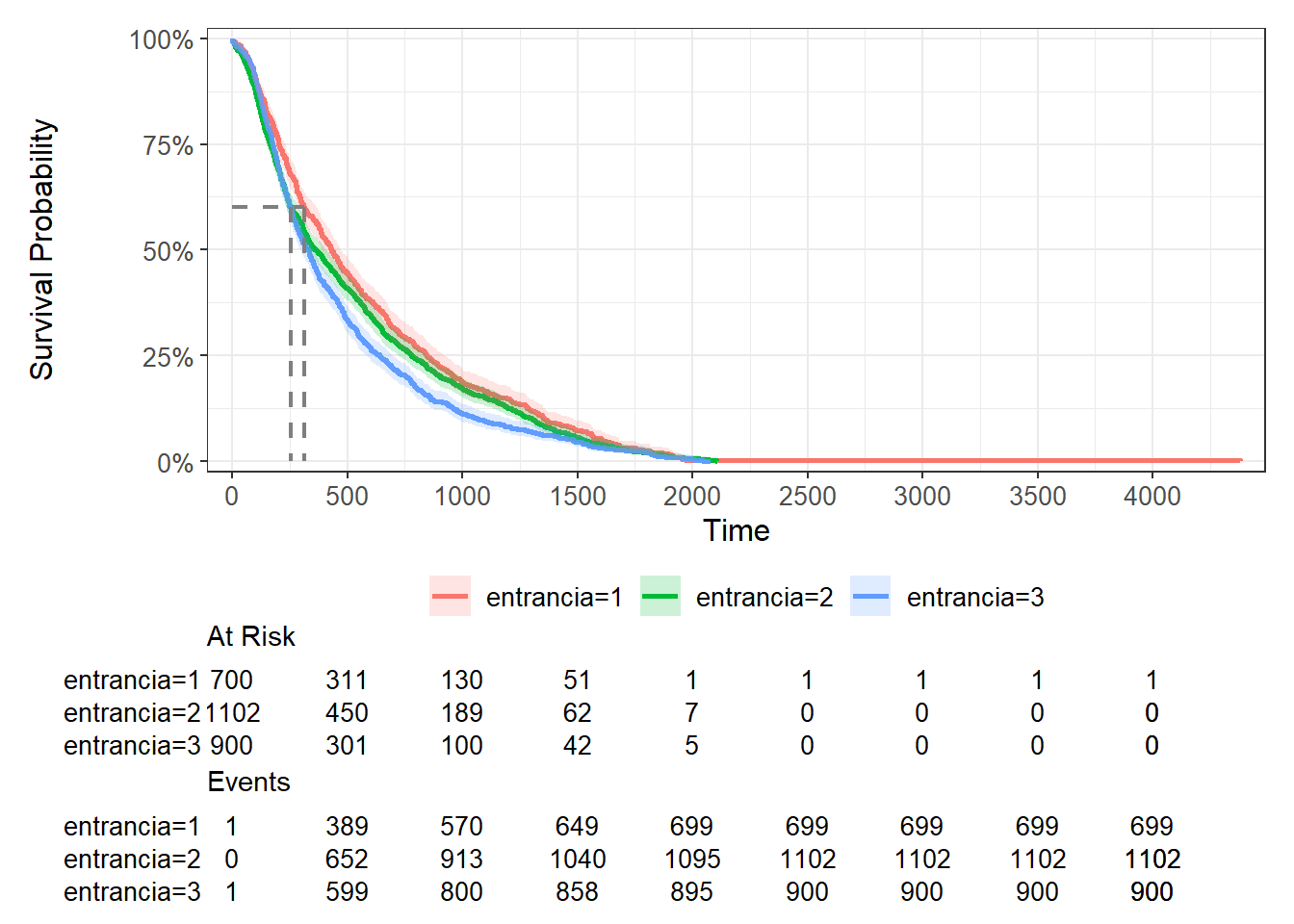
18.15.1 Função de incidência cumulativa
base <- base |>
mutate(evento = as.factor(evento))fit_cs1 <- survfit(Surv(tempo, evento) ~ entrancia, data = base)ggcuminc(fit_cs1,
outcome = "decidido") +
add_confidence_interval() +
labs(title="Risco para decidido")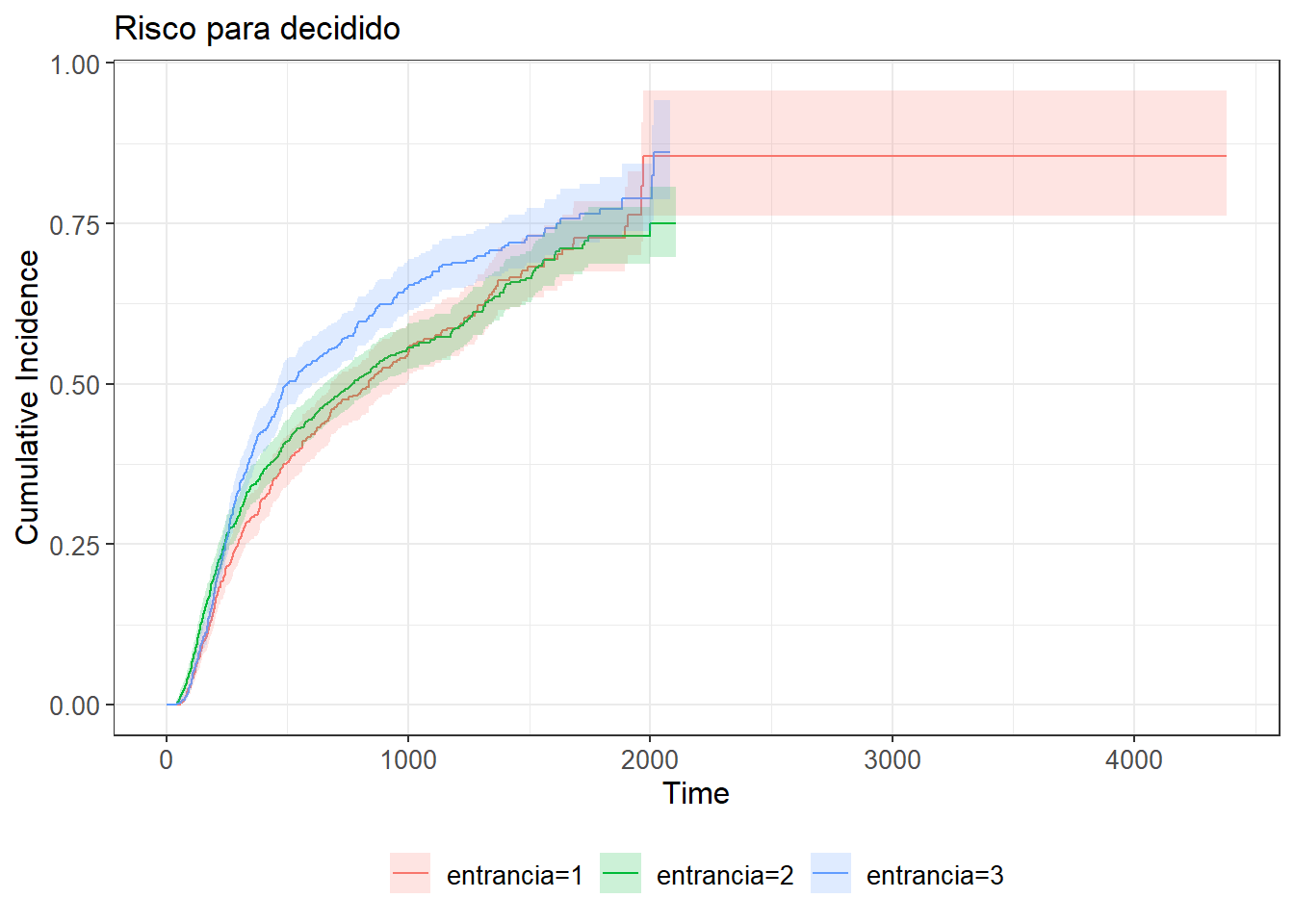
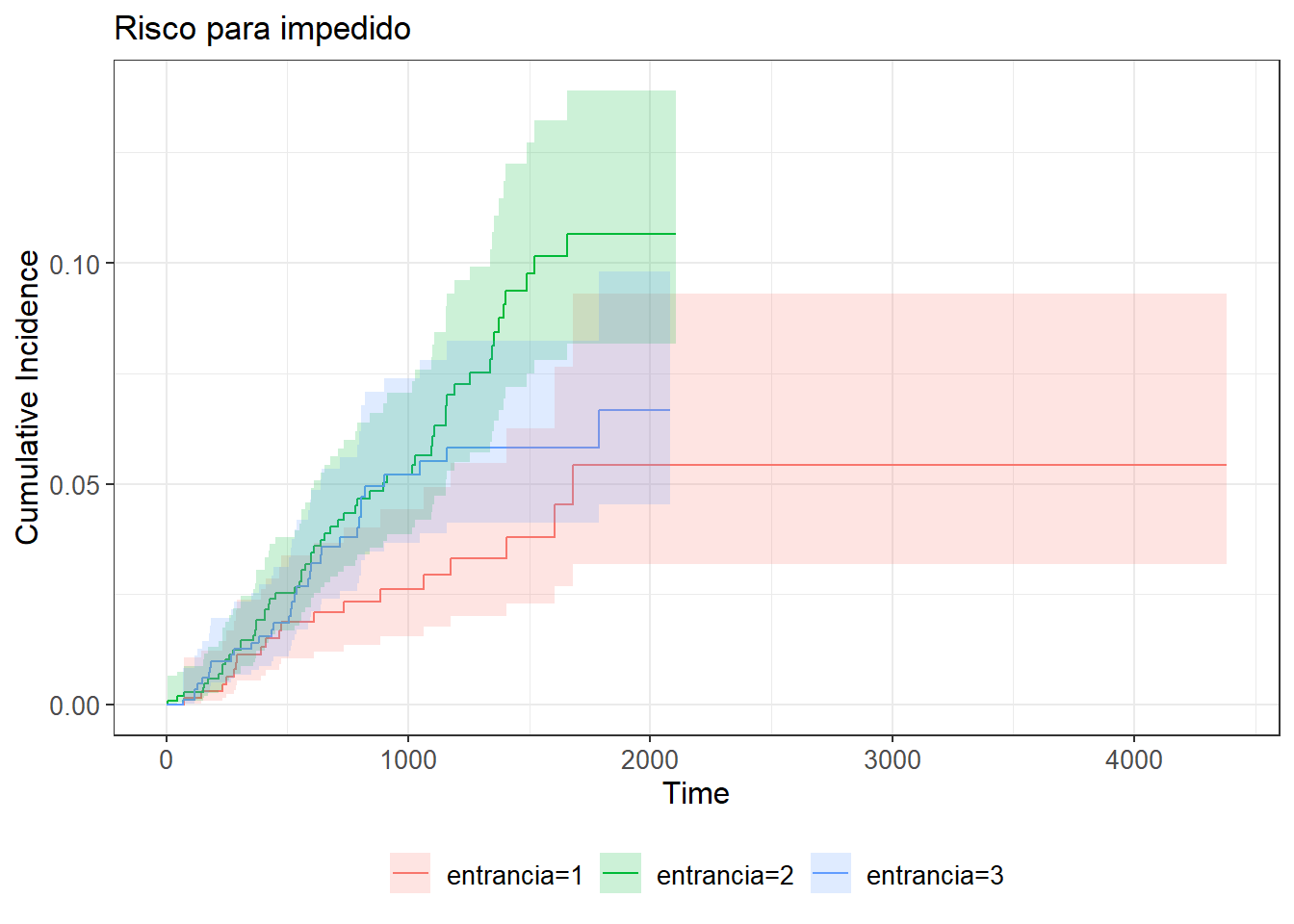
ggcuminc(fit_cs1,
outcome = "impedido") +
add_confidence_interval() +
labs(title="Risco para impedido")