install.packages("remotes","tidyverse","httr", "jsonlite","usethis","janitor", "here","modelsummary","gt")
remotes::install_github("courtsbr/JurisMiner")16 Aula Prática: Coleta e Análise de Dados sobre Homicídio Qualificado
16.1 Introdução à Aula Prática: Coleta de Dados no DataJud
Nesta aula prática, vamos aprender como coletar dados processuais utilizando a Base Nacional de Dados do Poder Judiciário (DataJud), mantida pelo Conselho Nacional de Justiça (CNJ). O DataJud é o sistema responsável pelo armazenamento centralizado de dados e metadados de todos os processos judiciais brasileiros, físicos ou eletrônicos, e será a base que utilizaremos ao longo do curso.
16.2 Acesso ao DataJud
O DataJud pode ser acessado diretamente no site do CNJ 🔗:
https://www.cnj.jus.br/sistemas/datajud/
A plataforma fornece dados atualizados para diversos os ramos da Justiça brasileira, agrupados e padronizados para permitir análises estatísticas e jurimétricas.
16.3 Autenticação e Chave Pública
Para acessar os dados via API, utilizaremos a API Pública do DataJud, documentada em:
https://datajud-wiki.cnj.jus.br/api-publica/
A autenticação é feita por meio de uma chave pública, disponibilizada pelo DPJ/CNJ. A chave 🔑 pode ser obtida no seguinte endereço:
https://datajud-wiki.cnj.jus.br/api-publica/acesso
Essa chave será utilizada diretamente no código em R (ou Python), permitindo realizar consultas autenticadas aos dados processuais.
16.4 Endpoints, Rotas e Seleção de Tribunais
Para realizar nossas consultas, precisamos escolher os endpoints disponíveis, indicando o tribunal desejado. Os endpoints estão detalhados em:
https://datajud-wiki.cnj.jus.br/api-publica/endpoints
É possível consultar processos de de diversos ramos da Justiça brasileira:
- Tribunais Superiores
- Justiça Federal
- Justiça Estadual
- Justiça do Trabalho
- Justiça Eleitoral
- Justiça Militar
No nosso estudo, utilizaremos os dados do Tribunal de Justiça do Tocantins (TJTO).
16.5 Tipos de Consultas Possíveis
A API permite diferentes modalidades de consulta 🔍, como:
- Pesquisa por número do processo
- Pesquisa paginada
- Pesquisa por classe
- Pesquisa por assunto
- …
O DataJud também disponibiliza exemplos de código em Python e R, acessíveis na aba de exemplos:
16.6 Glossário de Variáveis
O DataJud define nomes específicos para cada uma das variáveis retornadas pela API. O significado de cada termo pode ser consultado no glossário oficial:
https://datajud-wiki.cnj.jus.br/api-publica/glossario
Esse glossário é essencial para interpretar corretamente os dados coletados.
16.7 Seleção do Assunto de Interesse
Em geral, ao iniciar uma pesquisa empírica, precisamos definir o assunto processual a ser analisado. Para isso, utilizamos o Sistema de Gestão de Tabelas Processuais Unificadas:
https://www.cnj.jus.br/sgt/consulta_publica_assuntos.php
No nosso caso, o foco inicial seria Direito Penal/Crimes Contra a Vida, que inclui subcategorias como:
- 10915 — Aborto
- 12091 — Feminicídio
- 12130 — Homicídio Agravado pela Prática de Extermínio de Seres Humanos
- 3371 — Homicídio Privilegiado
- 3372 — Homicídio Qualificado
- 15177 — Homicídio Qualificado Contra Menor de 14 Anos (Lei Henry Borel)
- 3370 — Homicídio Simples
- 3373 — Induzimento, Instigação ou Auxílio a Suicídio
- 3375 — Infanticídio
Poderíamos escolher todas ou algumas dessas categorias para nossa análise.
16.8 Escolha Alternativa: Pesquisa por Classe
Nesta aula, porém, seguiremos um caminho alternativo: em vez de selecionar um assunto específico, trabalharemos com a classe processual.
Selecionamos a seguinte classe:
Processo Criminal → Procedimento Comum → Ação Penal de Competência do Júri
Código: 282
Essa classe captura processos de crimes dolosos contra a vida julgados pelo Tribunal do Júri, alinhados ao nosso objetivo analítico. Entretanto, muitos dos assuntos acima listados estarão presentes. Alám disso, limitamos os nossos processos à Instância de 1º Grau (G1).
16.9 Fase Muito Importante
A etapa que descrevemos até aqui é fundamental em qualquer pesquisa empírica que utilize o DataJud ou outras bases de dados judiciais. As escolhas feitas nesta fase, como a definição do assunto, da classe processual e dos critérios de filtragem, influenciam diretamente o desenho amostral que construiremos.
Uma boa seleção inicial garante maior precisão, consistência e relevância dos resultados. Por isso, é essencial conduzir essa etapa com atenção, calma e organização. Quanto mais cuidadosa for a definição desses parâmetros, melhor será a qualidade da extração dos dados e, consequentemente, das análises que realizaremos nas próximas fases do curso.
16.10 Colocando a Mão na Massa: Coleta de Dados no DataJud
16.10.1 Instalando os pacotes necessários
16.10.2 Carregando os pacotes necessários
library(tidyverse)
library(usethis)
library(janitor)
library(modelsummary)
library(gt)
library(JurisMiner)16.10.3 Criando um projeto para o curso
usethis::create_project("tjtomov")16.10.4 Crie a estrutura do projeto
dir.create("data")
dir.crate("data-raw")16.10.5 Importar a função do datajud
O script abaixo irá carregar na sua sessão do R uma função chamada datajud, que será utilizada para baixar os dados sobre homicídio.
source("https://gist.githubusercontent.com/jjesusfilho/b4634119b2d075ac54107d87fa6f22c7/raw/285fbfbec85223d3f394e00fed9d14804a1e5e89/baixar_datajud.R")
source("https://gist.githubusercontent.com/jjesusfilho/b4634119b2d075ac54107d87fa6f22c7/raw/285fbfbec85223d3f394e00fed9d14804a1e5e89/ler_datajud.R")16.10.6 Baixando os Dados Processuais
O código abaixo extrairá os dados da classe 282 do grau G1 do Tribunal de Justiça do Tocantins e salvará todas essas informações em arquivos jsons.
baixar_datajud(tamanho = 100, codigo_classe = 282, grau = "G1", diretorio = "data-raw")16.10.7 Lendo os dados processuais
dados_basicos <- ler_datajud(diretorio = "data-raw")Agora vamos analisar a estrutura do dados_basicos para identificar onde cada informação relevante está localizada. Esse mapeamento é essencial porque nos permite compreender exatamente como os dados estão organizados e, assim, definir qual tipo de extração precisamos realizar para trabalhar com informações de movimentação, órgãos julgadores, assuntos e outras características presentes no arquivo.
16.10.8 Analisando as Informações Extraídas
Órgão Julgador dos Processos
Vamos criar um banco que contenha o número do processo e o órgão julgador responsável por cada caso. Em seguida, analisaremos a frequência de processos por órgão julgador, tanto considerando apenas processos únicos quanto incluindo processos duplicados.
# Criar um dataframe com número do processo e órgão julgador
julgador <- dados_basicos |>
select(processo = numeroProcesso, orgaoJulgador) |> # Faço a seleção e renomeio a coluna
unnest(orgaoJulgador) |> # Como orgaoJulgador é um dataframe, preciso "desempacotar" os dados
janitor::clean_names() # Deixo os nomes padronizados
nrow(julgador) # número total de processos[1] 8432Observa-se um total de 8432 processos, mas alguns podem estar duplicados. Vamos investigar essa questão. Abaixo está o código para identificar e analisar processos únicos e duplicados.
# Vamos verificar se existem processos duplicados.
julgador_uni <- julgador |>
distinct(processo, .keep_all = TRUE)
nrow(julgador_uni) # numero total de processos únicos[1] 8287nrow(julgador) - nrow(julgador_uni) # número de processos duplicados[1] 145# Vamos analisar os processos duplicados
julgador_dup <- julgador %>%
filter(duplicated(processo) | duplicated(processo, fromLast = TRUE))
## Esse comando pega todas as linhas após a primeira ocorrência ou
## Pega todas as linhas antes da última ocorrência e verifica duplicação
## Vamos ver quantos processos duplicados temos:
nrow(julgador_dup) # número de processos duplicados[1] 289unique(julgador_dup$processo) |> length() # número de processos únicos que estão duplicados[1] 144O total de processos únicos foi de 8.287, e identificamos 144 processos duplicados. Agora, vamos verificar se essas duplicações ocorreram em razão de alguma mudança de órgão julgador. Para isso, vamos pivotar os dados e criar uma variável que indique se houve alteração no órgão julgador para cada processo duplicado.
## Analisando se houve troca de orgaõ julgador e por isso é duplicado
# 1. Criar ordem dentro de cada processo 1, para primeira vez e 2 para a segunda vez....
julgador_dup_ord <- julgador_dup %>%
group_by(processo) %>%
mutate(orgao_id = row_number()) %>%
ungroup()
# 2. Pivotar para formato wide, selciono e indico o nome que será dado
julgador_wide <- julgador_dup_ord %>%
select(processo, orgao_id, nome) %>%
pivot_wider(
names_from = orgao_id,
values_from = nome,
names_prefix = "julgador"
)
# 3. Variável indicando mudança
julgador_wide <- julgador_wide %>%
rowwise() %>%
mutate(
mudou_orgao = n_distinct(c_across(starts_with("julgador")), na.rm = TRUE) > 1
) %>%
ungroup()
# - > pega todas as colunas cujo nome começa com "julgador", transforma em vetores e verifica se é distinto
julgador_wide %>%
count(mudou_orgao, sort = TRUE) %>%
mutate(
mudou_orgao = ifelse(mudou_orgao, "Sim", "Não")
) %>%
knitr::kable(
caption = "Frequência de processos que mudaram de órgão julgador"
)| mudou_orgao | n |
|---|---|
| Não | 93 |
| Sim | 51 |
Observamos que 93 processos não mudaram de órgão julgador e 51 passaram por alteração. Agora precisamos definir como trataremos esses casos: se consideraremos apenas o órgão julgador final, se adotaremos o órgão julgador inicial como referência ou excluímos. Mas ainda precisamos observar que há 93 processos que aparecem duplicados, mesmo sem mudança de órgão julgador. O que pode estar acontecendo nesses casos?
LIMPEZA DOS DADOS
Escolha e Justificativa
Motivos Possíveis: Recursos, mudanças para varas expecializadas, desclassificação, desforamento, entre outros.
Escolha: Vamos excluir os processos que mudaram de órgão julgador, mantendo apenas aqueles que permaneceram no mesmo órgão. Depois analisaremos os processos duplicados restantes.
Justificativa: A mudança de órgão julgador pode indicar transferências ou redistribuições que podem afetar a análise do tempo do processo. Para garantir a consistência dos dados e evitar vieses, mantemos somente aqueles permaneceram no mesmo órgão julgador ao longo do tempo.
# Vamos retirar os processos que mudaram de orgão julgador
db_limpo <- dados_basicos %>%
anti_join(julgador_wide %>% filter(mudou_orgao == TRUE),
by = c("numeroProcesso" = "processo"))Vamos focar nos processos únicos para analisar a frequência de órgãos julgadores e descrever os resultados graficamente e em tabelas.
freq_j_u <- julgador_uni %>%
count(nome) %>%
arrange(desc(n)) %>%
mutate(perc = round(100 * n / sum(n), 1))
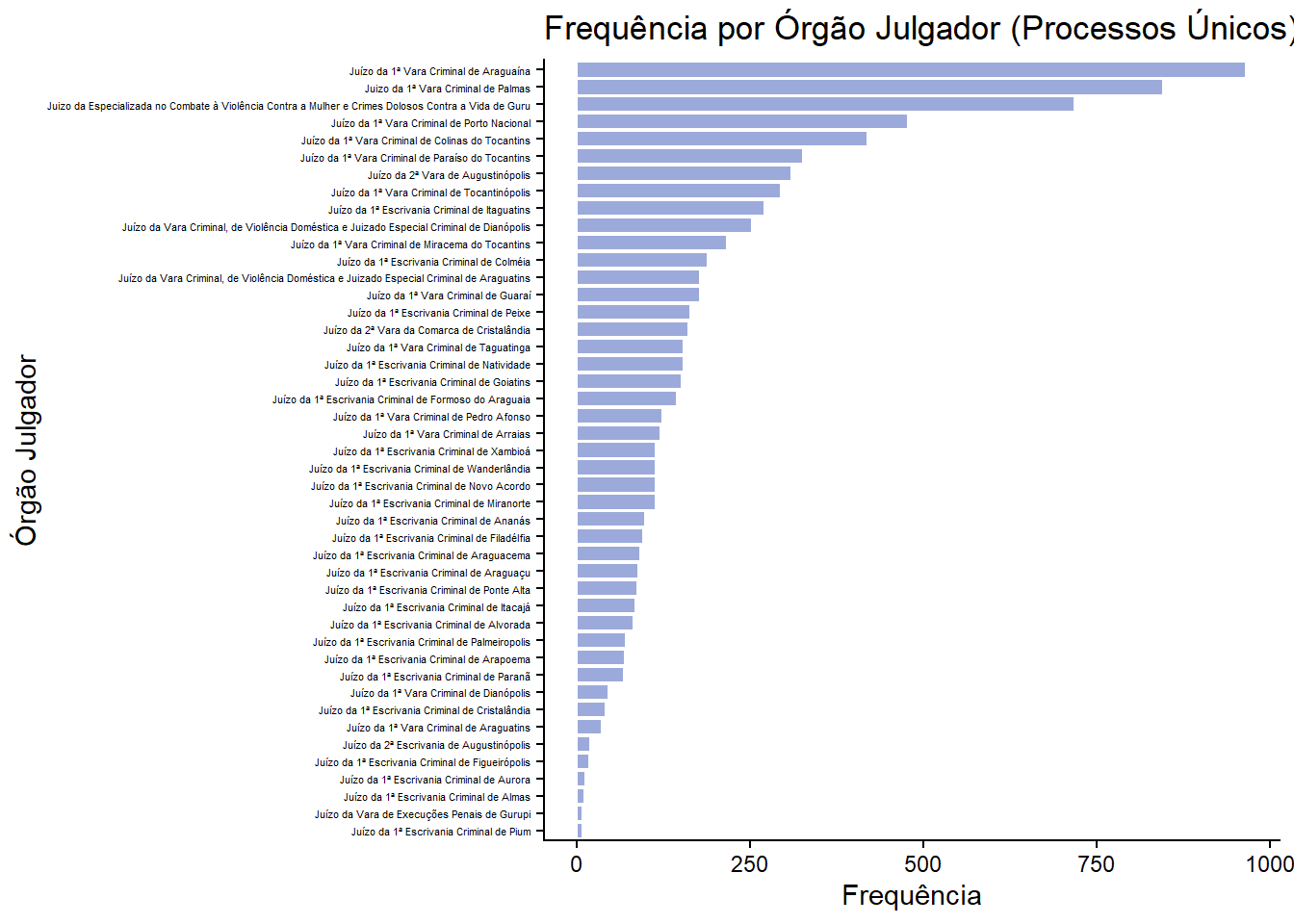
ggplot(freq_j_u, aes(x = reorder(nome, n), y = n)) +
geom_col(fill = "#7185cc", color = "white", alpha = 0.7) +
coord_flip() +
labs(
title = "Frequência por Órgão Julgador (Processos Únicos)",
x = "Órgão Julgador",
y = "Frequência"
) +
theme_classic()+
theme(
axis.text.y = element_text(size = 4) # tamanho da letra das categorias
)
freq_j_u |>
gt() |>
tab_header(
title = "Frequência por Órgão Julgador (Processos Únicos)"
) |>
cols_label(
nome = "Órgão Julgador",
n = "Frequência",
perc = "Percentual"
)| Frequência por Órgão Julgador (Processos Únicos) | ||
|---|---|---|
| Órgão Julgador | Frequência | Percentual |
| Juízo da 1ª Vara Criminal de Araguaína | 965 | 11.6 |
| Juizo da 1ª Vara Criminal de Palmas | 846 | 10.2 |
| Juizo da Especializada no Combate à Violência Contra a Mulher e Crimes Dolosos Contra a Vida de Guru | 717 | 8.7 |
| Juízo da 1ª Vara Criminal de Porto Nacional | 477 | 5.8 |
| Juízo da 1ª Vara Criminal de Colinas do Tocantins | 419 | 5.1 |
| Juízo da 1ª Vara Criminal de Paraíso do Tocantins | 326 | 3.9 |
| Juízo da 2ª Vara de Augustinópolis | 309 | 3.7 |
| Juízo da 1ª Vara Criminal de Tocantinópolis | 294 | 3.5 |
| Juízo da 1ª Escrivania Criminal de Itaguatins | 271 | 3.3 |
| Juízo da Vara Criminal, de Violência Doméstica e Juizado Especial Criminal de Dianópolis | 252 | 3.0 |
| Juízo da 1ª Vara Criminal de Miracema do Tocantins | 216 | 2.6 |
| Juízo da 1ª Escrivania Criminal de Colméia | 189 | 2.3 |
| Juízo da Vara Criminal, de Violência Doméstica e Juizado Especial Criminal de Araguatins | 178 | 2.1 |
| Juízo da 1ª Vara Criminal de Guaraí | 177 | 2.1 |
| Juízo da 1ª Escrivania Criminal de Peixe | 163 | 2.0 |
| Juízo da 2ª Vara da Comarca de Cristalândia | 160 | 1.9 |
| Juízo da 1ª Escrivania Criminal de Natividade | 154 | 1.9 |
| Juízo da 1ª Vara Criminal de Taguatinga | 154 | 1.9 |
| Juízo da 1ª Escrivania Criminal de Goiatins | 151 | 1.8 |
| Juízo da 1ª Escrivania Criminal de Formoso do Araguaia | 144 | 1.7 |
| Juízo da 1ª Vara Criminal de Pedro Afonso | 123 | 1.5 |
| Juízo da 1ª Vara Criminal de Arraias | 121 | 1.5 |
| Juízo da 1ª Escrivania Criminal de Miranorte | 113 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Novo Acordo | 113 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Wanderlândia | 113 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Xambioá | 113 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Ananás | 98 | 1.2 |
| Juízo da 1ª Escrivania Criminal de Filadélfia | 95 | 1.1 |
| Juízo da 1ª Escrivania Criminal de Araguacema | 91 | 1.1 |
| Juízo da 1ª Escrivania Criminal de Araguaçu | 88 | 1.1 |
| Juízo da 1ª Escrivania Criminal de Ponte Alta | 87 | 1.0 |
| Juízo da 1ª Escrivania Criminal de Itacajá | 84 | 1.0 |
| Juízo da 1ª Escrivania Criminal de Alvorada | 82 | 1.0 |
| Juízo da 1ª Escrivania Criminal de Palmeiropolis | 70 | 0.8 |
| Juízo da 1ª Escrivania Criminal de Arapoema | 69 | 0.8 |
| Juízo da 1ª Escrivania Criminal de Paranã | 67 | 0.8 |
| Juízo da 1ª Vara Criminal de Dianópolis | 46 | 0.6 |
| Juízo da 1ª Escrivania Criminal de Cristalândia | 41 | 0.5 |
| Juízo da 1ª Vara Criminal de Araguatins | 35 | 0.4 |
| Juízo da 2ª Escrivania de Augustinópolis | 19 | 0.2 |
| Juízo da 1ª Escrivania Criminal de Figueirópolis | 18 | 0.2 |
| Juízo da 1ª Escrivania Criminal de Aurora | 12 | 0.1 |
| Juízo da 1ª Escrivania Criminal de Almas | 11 | 0.1 |
| Juízo da 1ª Escrivania Criminal de Pium | 8 | 0.1 |
| Juízo da Vara de Execuções Penais de Gurupi | 8 | 0.1 |
Questão
Como podemos fazer a nossa análise de movimento considerando que comarcas distintas possuem diferentes volumes de processos? Devemos agrupar as comarcas maiores e as menores? Quais critérios utilizar para isso? Deixamos varas criminais separada de especializadas?
Sistema dos Processos
Aqui avaliamos se os processos pertencem ao sistema sistema eletrônico de processos judiciais EPROC ou a outro sistema.
sistema <- db_limpo |>
select(processo = numeroProcesso, sistema) |>
unnest(sistema) |>
janitor::clean_names()
freq_sistema <- sistema %>%
count(nome) %>%
arrange(desc(n))
freq_sistema |>
gt() |>
tab_header(
title = "Frequência por Sistema (Processos Únicos)"
) |>
cols_label(
nome = "Sistema",
n = "Frequência",
)| Frequência por Sistema (Processos Únicos) | |
|---|---|
| Sistema | Frequência |
| EPROC | 8323 |
| Inválido | 4 |
| Outros | 2 |
Com base na tabela acima, podemos observar a distribuição dos processos entre os sistemas Eletrônico e Físico. Observa-se a existência somente de processos eletrônicos, mas 4 foram declaros inválidos e 2 Outros. O que fazer com esses casos? Devemos excluí-los da análise ou mantê-los?
LIMPEZA DOS DADOS
Escolha e Justificativa
Motivos Possíveis: Citação em outros estados, entre outros.
Escolha: Vamos excluir todos os processos que não são EPROC.
Justificativa: Não sabemos ao certo os motivos que levaram a um processo ser classificado como inválido ou outros. Além disso, não sabemos como essa classificação afeta a movimentação. Portanton, vamos excluir todos que não foram EPROC e deixar nossa amostra mais homogênea.
# Vamos retirar os processos que mudaram de orgão julgador
db_limpo <- db_limpo %>%
anti_join(sistema %>% filter(!nome == "EPROC"),
by = c("numeroProcesso" = "processo"))Formato do Processo
Aqui avaliamos se os processos são do tipo Eletrônico ou Físico.
formato <- db_limpo |>
select(processo = numeroProcesso, formato) |>
unnest(formato) |>
janitor::clean_names()
freq_formato <- formato %>%
count(nome) %>%
arrange(desc(n))
freq_formato |>
gt() |>
tab_header(
title = "Frequência por Formato (Processos Únicos)"
) |>
cols_label(
nome = "Formato",
n = "Frequência",
)| Frequência por Formato (Processos Únicos) | |
|---|---|
| Formato | Frequência |
| Eletrônico | 8322 |
Observa-se que 100% dos processos estão no formato Eletrônico. Dessa forma, não há necessidade de excluir nenhum processo com base nesse critério.
Classe Processual
Como fizemos nossa busca por classe processual, 282, deveríamos ter somente essa classe. Vamos verificar se há outras classes presentes nos dados.
classe <- db_limpo |>
select(processo = numeroProcesso, classe) |>
unnest(classe) |>
janitor::clean_names()
freq_classe <- classe %>%
count(nome) %>%
arrange(desc(n))
freq_classe |>
gt() |>
tab_header(
title = "Frequência por Classe (Processos Únicos)"
) |>
cols_label(
nome = "Classe",
n = "Frequência",
)| Frequência por Classe (Processos Únicos) | |
|---|---|
| Classe | Frequência |
| Ação Penal de Competência do Júri | 8322 |
Conforme esperado pela nossa consulta inicial, todos os processos pertencem à classe Ação Penal de Competência do Júri (282). Portanto, não há necessidade de excluir nenhum processo com base nesse critério.
Assuntos Processuais
Vamos extrair e analisar os assuntos processuais associados a cada processo. Vamos fazer a extração e veja que o resultado é uma coluna com processo e a outra com o assunto. Se tivermos mais assuntos por processo, esse será duplicado.
# manter só linhas em que 'assuntos' é um data.frame
assuntos <- db_limpo |>
filter(map_lgl(assuntos, is.data.frame)) |>
select(processo = numeroProcesso, assuntos) |>
unnest(assuntos) |>
clean_names()
# Processos únicos
nrow(assuntos %>%
distinct(processo, .keep_all = TRUE)) # número total de processos únicos[1] 8228freq_assunto <- assuntos |>
count(nome) |>
arrange(desc(n)) |>
mutate(perc_assunto = round(100 * n / sum(n), 1)) |>
mutate(perc_processo = round(100 * n / 8228, 1)) # considerando processos únicos
ggplot(freq_assunto, aes(x = reorder(nome, n), y = n)) +
geom_col(fill = "#7185cc", color = "white", alpha = 0.7) +
coord_flip() +
labs(
title = "Frequência por Assunto (Processos Únicos)",
x = "Assunto",
y = "Frequência"
) +
theme_classic()+
theme(
axis.text.y = element_text(size = 4)) # tamanho da letra das categorias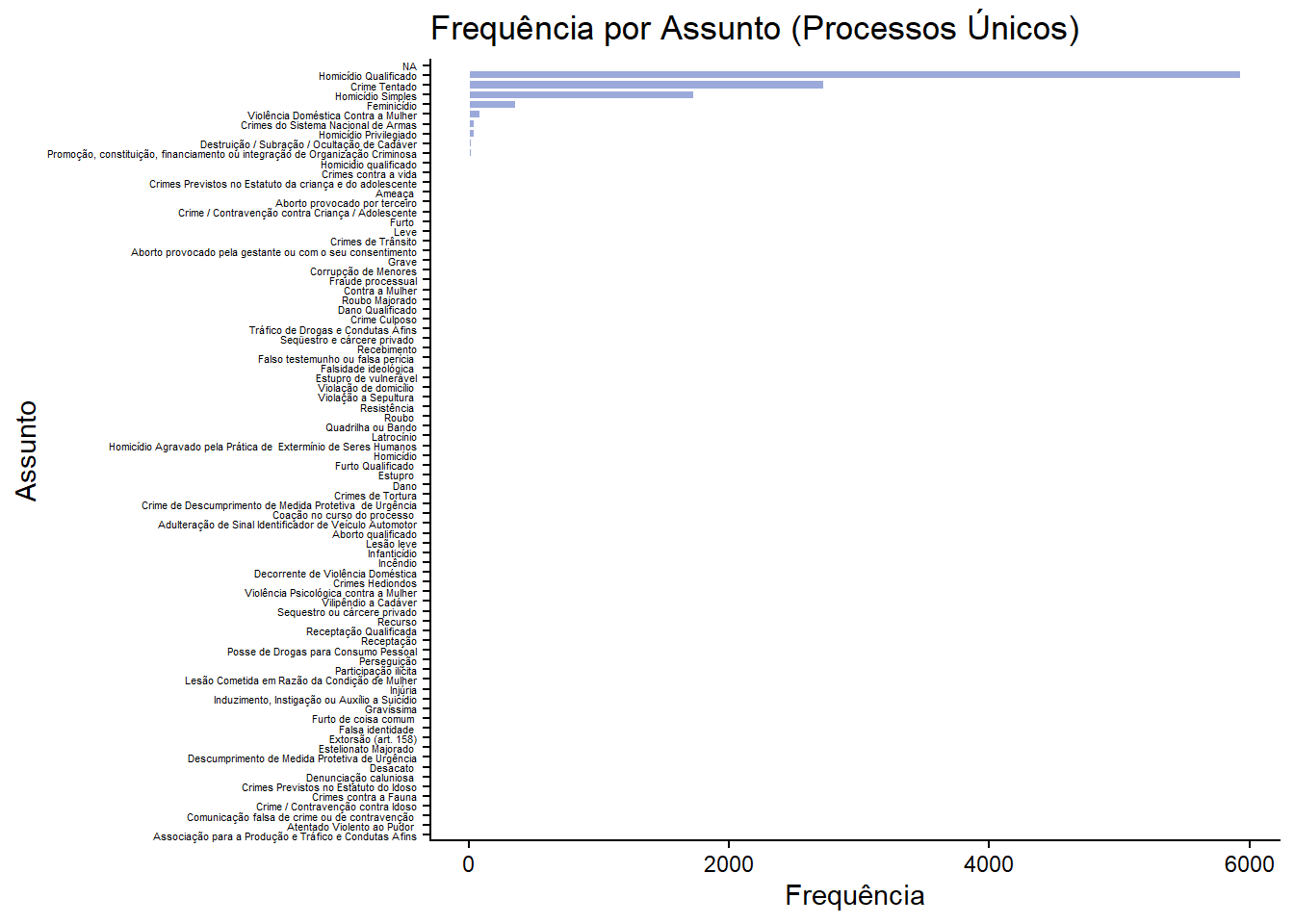
freq_assunto |>
gt() |>
tab_header(
title = "Frequência dos Assuntos"
) |>
cols_label(
nome = "Assunto",
n = "Frequência",
perc_assunto = "% Assuntos",
perc_processo = "% Processos"
)| Frequência dos Assuntos | |||
|---|---|---|---|
| Assunto | Frequência | % Assuntos | % Processos |
| Homicídio Qualificado | 5933 | 52.5 | 72.1 |
| Crime Tentado | 2733 | 24.2 | 33.2 |
| Homicídio Simples | 1731 | 15.3 | 21.0 |
| Feminicídio | 362 | 3.2 | 4.4 |
| Violência Doméstica Contra a Mulher | 91 | 0.8 | 1.1 |
| Crimes do Sistema Nacional de Armas | 47 | 0.4 | 0.6 |
| Homicídio Privilegiado | 45 | 0.4 | 0.5 |
| Destruição / Subração / Ocultação de Cadáver | 28 | 0.2 | 0.3 |
| Promoção, constituição, financiamento ou integração de Organização Criminosa | 24 | 0.2 | 0.3 |
| Homicidio qualificado | 20 | 0.2 | 0.2 |
| Crimes contra a vida | 18 | 0.2 | 0.2 |
| Crimes Previstos no Estatuto da criança e do adolescente | 17 | 0.2 | 0.2 |
| Ameaça | 15 | 0.1 | 0.2 |
| Aborto provocado por terceiro | 14 | 0.1 | 0.2 |
| Crime / Contravenção contra Criança / Adolescente | 13 | 0.1 | 0.2 |
| Furto | 12 | 0.1 | 0.1 |
| Aborto provocado pela gestante ou com o seu consentimento | 10 | 0.1 | 0.1 |
| Crimes de Trânsito | 10 | 0.1 | 0.1 |
| Leve | 10 | 0.1 | 0.1 |
| Grave | 9 | 0.1 | 0.1 |
| Corrupção de Menores | 8 | 0.1 | 0.1 |
| Contra a Mulher | 7 | 0.1 | 0.1 |
| Fraude processual | 7 | 0.1 | 0.1 |
| Crime Culposo | 6 | 0.1 | 0.1 |
| Dano Qualificado | 6 | 0.1 | 0.1 |
| Roubo Majorado | 6 | 0.1 | 0.1 |
| Estupro de vulnerável | 5 | 0.0 | 0.1 |
| Falsidade ideológica | 5 | 0.0 | 0.1 |
| Falso testemunho ou falsa perícia | 5 | 0.0 | 0.1 |
| Recebimento | 5 | 0.0 | 0.1 |
| Seqüestro e cárcere privado | 5 | 0.0 | 0.1 |
| Tráfico de Drogas e Condutas Afins | 5 | 0.0 | 0.1 |
| Resistência | 4 | 0.0 | 0.0 |
| Violação a Sepultura | 4 | 0.0 | 0.0 |
| Violação de domicílio | 4 | 0.0 | 0.0 |
| Aborto qualificado | 3 | 0.0 | 0.0 |
| Adulteração de Sinal Identificador de Veículo Automotor | 3 | 0.0 | 0.0 |
| Coação no curso do processo | 3 | 0.0 | 0.0 |
| Crime de Descumprimento de Medida Protetiva de Urgência | 3 | 0.0 | 0.0 |
| Crimes de Tortura | 3 | 0.0 | 0.0 |
| Dano | 3 | 0.0 | 0.0 |
| Estupro | 3 | 0.0 | 0.0 |
| Furto Qualificado | 3 | 0.0 | 0.0 |
| Homicídio | 3 | 0.0 | 0.0 |
| Homicídio Agravado pela Prática de Extermínio de Seres Humanos | 3 | 0.0 | 0.0 |
| Latrocínio | 3 | 0.0 | 0.0 |
| Quadrilha ou Bando | 3 | 0.0 | 0.0 |
| Roubo | 3 | 0.0 | 0.0 |
| NA | 3 | 0.0 | 0.0 |
| Crimes Hediondos | 2 | 0.0 | 0.0 |
| Decorrente de Violência Doméstica | 2 | 0.0 | 0.0 |
| Incêndio | 2 | 0.0 | 0.0 |
| Infanticídio | 2 | 0.0 | 0.0 |
| Lesão leve | 2 | 0.0 | 0.0 |
| Associação para a Produção e Tráfico e Condutas Afins | 1 | 0.0 | 0.0 |
| Atentado Violento ao Pudor | 1 | 0.0 | 0.0 |
| Comunicação falsa de crime ou de contravenção | 1 | 0.0 | 0.0 |
| Crime / Contravenção contra Idoso | 1 | 0.0 | 0.0 |
| Crimes Previstos no Estatuto do Idoso | 1 | 0.0 | 0.0 |
| Crimes contra a Fauna | 1 | 0.0 | 0.0 |
| Denunciação caluniosa | 1 | 0.0 | 0.0 |
| Desacato | 1 | 0.0 | 0.0 |
| Descumprimento de Medida Protetiva de Urgência | 1 | 0.0 | 0.0 |
| Estelionato Majorado | 1 | 0.0 | 0.0 |
| Extorsão (art. 158) | 1 | 0.0 | 0.0 |
| Falsa identidade | 1 | 0.0 | 0.0 |
| Furto de coisa comum | 1 | 0.0 | 0.0 |
| Gravíssima | 1 | 0.0 | 0.0 |
| Induzimento, Instigação ou Auxílio a Suicídio | 1 | 0.0 | 0.0 |
| Injúria | 1 | 0.0 | 0.0 |
| Lesão Cometida em Razão da Condição de Mulher | 1 | 0.0 | 0.0 |
| Participação ilícita | 1 | 0.0 | 0.0 |
| Perseguição | 1 | 0.0 | 0.0 |
| Posse de Drogas para Consumo Pessoal | 1 | 0.0 | 0.0 |
| Receptação | 1 | 0.0 | 0.0 |
| Receptação Qualificada | 1 | 0.0 | 0.0 |
| Recurso | 1 | 0.0 | 0.0 |
| Sequestro ou cárcere privado | 1 | 0.0 | 0.0 |
| Vilipêndio a Cadáver | 1 | 0.0 | 0.0 |
| Violência Psicológica contra a Mulher | 1 | 0.0 | 0.0 |
Assuntos tem um total de 11302 processos, sendo que o número de processos únicos é 8228. Isso indica que muitos processos têm mais de um assunto associado. Então a leitura da tabela acima deve considerar esses números. Podemos dizer que 5933 processos tiveram Homicídio Qualificado como assunto, 2733 tiveram Crime Tentado, e assim por diante. Existe sobreposição entre os assuntos.
Fizemos duas colunas, uma com percentual com base no total de assuntos (11302), % Assuntos, e outra com base no total de processos únicos (8228), % Processos. A segunda coluna é mais interessante, pois indica a proporção de processos que tiveram cada assunto.
Agora vamos olhar o assunto por processo, para ver quantos assuntos cada processo tem associado.
assuntos_wide <- assuntos %>%
group_by(processo, nome) %>% # garante uma linha por processo-assunto
summarise(valor = 1, .groups = "drop") %>%
pivot_wider(
names_from = nome,
values_from = valor,
values_fill = list(valor = 0) # preenche com 0 se não ocorreu
)
assuntos_wide %>%
slice_head(n = 10) %>%
select(1:8) %>%
gt() %>%
tab_header(
title = "Assuntos por Processo (Exemplo)"
)| Assuntos por Processo (Exemplo) | |||||||
|---|---|---|---|---|---|---|---|
| processo | Homicídio Simples | Crime Tentado | Homicídio Qualificado | Corrupção de Menores | Feminicídio | Violência Doméstica Contra a Mulher | Homicídio Privilegiado |
| 00000059520148272720 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 00000067320168272732 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 00000072320198272742 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 00000080820148272734 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 00000081220218272718 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 00000109320198272736 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 00000121120208272742 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 00000123520158272726 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 00000137020178272719 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 00000170620248272738 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
Agora cada linha é um processo único com todos os assuntos listados. Tivemos um total de 8228. Para o tribunal do Juri tem-se 5 tipos penais: Homicídio Qualificado, Homicídio Simples, Infanticídio, Aborto, Induzimento ao Suicídio e a partir de outubro de 24 o Feminicídio.
Questão:
Devemos incluir todos os assuntos ou focar apenas em alguns? Quais critérios utilizar para essa seleção?
LIMPEZA DOS DADOS
Escolha e Justificativa
Escolha: Vamos trabalhar somente com homicídio Qualificado, Simples e Feminicídio.
Justificativa: Acreditamos que esse esses processos possuem um perfil semelhante entre si, e diferente do infanticídio, aborto e induzimento ao suicídio.
# Vamos retirar os processos que mudaram de orgão julgador
assuntos_wide_limpo <- assuntos_wide %>%
mutate(
homic_bin = if_any(
c(
"Homicídio Qualificado",
"Homicídio Simples",
"Feminicídio",
"Homicidio qualificado",
"Homicídio",
"Homicídio Privilegiado",
"Crimes contra a vida"
),
~ .x == 1
) * 1
)
db_limpo <- db_limpo %>%
anti_join(assuntos_wide_limpo %>% filter(homic_bin == 0),
by = c("numeroProcesso" = "processo"))
nrow(db_limpo) # número total de processos após limpeza[1] 7921nrow(db_limpo %>%
distinct(numeroProcesso, .keep_all = TRUE)) # número total de processos únicos[1] 7829Ao final do procedimento, observamos que o banco de dados original continha 8.432 processos. Após as etapas de limpeza e organização, chegamos a 7.867 registros. No entanto, ainda identificamos a existência de processos duplicados. O total de processos únicos é de 7.775, o que significa que permanecem 92 processos duplicados para os quais ainda precisamos definir um tratamento adequado.
LIMPEZA DOS DADOS
Escolha e Justificativa
Escolha: Excluir os processos duplicados.
Justificativa: Como não está claro o motivo dessa duplicação e quais seus impactos sobre a movimentação, vamos optar pela exclusão desses processos.Note que poderiamos identificar esses processos e fazermos uma análise mais detalhada sobre eles.
Motivos: Insidente de insanidade mental, por exemplo. Processo separado mas com mesmo número.
# Vamos retirar os processos que mudaram de orgão julgador
db_limpo <- db_limpo %>%
anti_join(julgador_dup,
by = c("numeroProcesso" = "processo"))Concluímos a limpeza com 7.683 processos, que serão a base da análise de movimentação. Antes de prosseguir, vamos reorganizar as tabelas anteriores de julgador, assunto e demais variáveis, usando agora apenas esse banco de dados limpo.
TABELAS FINAIS APÓS LIMPEZA DOS DADOS
Com os dados limpos vamos criar uma data.frame de julgados final. Nesse vamos deixar o processo, o órgão julgador, e criar variáveis que indiquem se o órgão é especializado ou não, e se está entre os 5 com maior volume de processos.
# JULGADOR
julgador_final <- db_limpo |>
select(processo = numeroProcesso, orgaoJulgador) |>
unnest(orgaoJulgador) |>
janitor::clean_names()
# Alterando o nome para facilitar a leitura e excluindo o cod do IBGE
julgador_final <- julgador_final %>%
rename(orgao_julgador = nome) %>%
select(-codigo_municipio_ibge)
# Construindo a tabela final do orgão julgador
freq_j_f <- julgador_final %>%
count(orgao_julgador) %>%
arrange(desc(n)) %>%
mutate(perc = round(100 * n / sum(n), 1))
freq_j_f |>
gt() |>
tab_header(
title = "Frequência por Órgão Julgador (Processos Únicos)"
) |>
cols_label(
orgao_julgador = "Órgão Julgador",
n = "Frequência",
perc = "Percentual"
)| Frequência por Órgão Julgador (Processos Únicos) | ||
|---|---|---|
| Órgão Julgador | Frequência | Percentual |
| Juízo da 1ª Vara Criminal de Araguaína | 948 | 12.3 |
| Juizo da 1ª Vara Criminal de Palmas | 824 | 10.7 |
| Juizo da Especializada no Combate à Violência Contra a Mulher e Crimes Dolosos Contra a Vida de Guru | 690 | 8.9 |
| Juízo da 1ª Vara Criminal de Porto Nacional | 425 | 5.5 |
| Juízo da 1ª Vara Criminal de Colinas do Tocantins | 390 | 5.0 |
| Juízo da 1ª Vara Criminal de Paraíso do Tocantins | 313 | 4.0 |
| Juízo da 2ª Vara de Augustinópolis | 276 | 3.6 |
| Juízo da 1ª Vara Criminal de Tocantinópolis | 271 | 3.5 |
| Juízo da 1ª Escrivania Criminal de Itaguatins | 257 | 3.3 |
| Juízo da Vara Criminal, de Violência Doméstica e Juizado Especial Criminal de Dianópolis | 219 | 2.8 |
| Juízo da 1ª Vara Criminal de Miracema do Tocantins | 203 | 2.6 |
| Juízo da 1ª Escrivania Criminal de Colméia | 180 | 2.3 |
| Juízo da 1ª Vara Criminal de Guaraí | 164 | 2.1 |
| Juízo da 1ª Escrivania Criminal de Peixe | 159 | 2.1 |
| Juízo da Vara Criminal, de Violência Doméstica e Juizado Especial Criminal de Araguatins | 155 | 2.0 |
| Juízo da 1ª Escrivania Criminal de Natividade | 150 | 1.9 |
| Juízo da 2ª Vara da Comarca de Cristalândia | 149 | 1.9 |
| Juízo da 1ª Vara Criminal de Taguatinga | 142 | 1.8 |
| Juízo da 1ª Escrivania Criminal de Formoso do Araguaia | 141 | 1.8 |
| Juízo da 1ª Escrivania Criminal de Goiatins | 137 | 1.8 |
| Juízo da 1ª Vara Criminal de Arraias | 118 | 1.5 |
| Juízo da 1ª Escrivania Criminal de Miranorte | 111 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Wanderlândia | 110 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Xambioá | 110 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Novo Acordo | 108 | 1.4 |
| Juízo da 1ª Vara Criminal de Pedro Afonso | 107 | 1.4 |
| Juízo da 1ª Escrivania Criminal de Filadélfia | 95 | 1.2 |
| Juízo da 1ª Escrivania Criminal de Ananás | 92 | 1.2 |
| Juízo da 1ª Escrivania Criminal de Araguaçu | 82 | 1.1 |
| Juízo da 1ª Escrivania Criminal de Ponte Alta | 77 | 1.0 |
| Juízo da 1ª Escrivania Criminal de Araguacema | 73 | 0.9 |
| Juízo da 1ª Escrivania Criminal de Alvorada | 72 | 0.9 |
| Juízo da 1ª Escrivania Criminal de Arapoema | 68 | 0.9 |
| Juízo da 1ª Escrivania Criminal de Palmeiropolis | 65 | 0.8 |
| Juízo da 1ª Escrivania Criminal de Itacajá | 64 | 0.8 |
| Juízo da 1ª Escrivania Criminal de Paranã | 61 | 0.8 |
| Juízo da 1ª Vara Criminal de Dianópolis | 37 | 0.5 |
| Juízo da 1ª Escrivania Criminal de Cristalândia | 35 | 0.5 |
| Juízo da 1ª Vara Criminal de Araguatins | 27 | 0.3 |
| Juízo da 2ª Escrivania de Augustinópolis | 18 | 0.2 |
| Juízo da Vara de Execuções Penais de Gurupi | 8 | 0.1 |
| Juízo da 1ª Escrivania Criminal de Aurora | 6 | 0.1 |
Identificando a Varas Especializadas e as Varas com Maior Volume de Processos
# Identificando as Varas Especializadas
julgador_final <- julgador_final %>%
mutate(
vara_espec = ifelse(
orgao_julgador %in% c(
"Juizo da Especializada no Combate à Violência Contra a Mulher e Crimes Dolosos Contra a Vida de Guru",
"Juízo da Vara Criminal, de Violência Doméstica e Juizado Especial Criminal de Dianópolis",
"Juízo da Vara Criminal, de Violência Doméstica e Juizado Especial Criminal de Araguatins"
),
1, 0
)
)
# Identificando as varas com maior volume de processos (top 5)
julgador_final <- julgador_final %>%
mutate(
volume_top5 = ifelse(
orgao_julgador %in% c(
"Juízo da 1ª Vara Criminal de Araguaína",
"Juizo da 1ª Vara Criminal de Palmas",
"Juízo da 1ª Vara Criminal de Porto Nacional",
"Juízo da 1ª Vara Criminal de Colinas do Tocantins",
"Juízo da 1ª Vara Criminal de Paraíso do Tocantins"
),
1, 0
)
)Agora começaremos a montar o banco de dados final, agregando todos os bancos que já organizamos. Vamos unir as informações de órgão julgador, sistema, formato, classe e assunto além das variáveis binárias que criamos anteriormente.
sistema_final <- db_limpo |>
select(processo = numeroProcesso, sistema) |>
unnest(sistema) |>
janitor::clean_names()
sistema_final <- sistema_final %>%
rename(sistema = nome)
bd_final <- julgador_final |>
left_join(sistema_final, by = c("processo" = "processo")) |>
left_join(formato, by = c("processo" = "processo")) |>
left_join(classe, by = c("processo" = "processo"))
bd_final <- bd_final %>%
rename(
cod_julgador = codigo.x,
cod_sistema = codigo.y,
cod_formato = codigo.x.x,
cod_classe = codigo.y.y,
formato = nome.x,
classe = nome.y
)Agora vamos organizar o banco de dados de assuntos. Vamos utilizar o nosso assunto_wide para trazer para o nosso banco de dados final e crarmos variáveis binárias.
Primeiro vamos ver se todos os assuntos estão presentes e depois vamos deixar somente aqueles que possuem soma maior que zero.
bd_final <- bd_final |>
left_join(assuntos_wide_limpo, by = c("processo" = "processo"))
tabela_somas <- bd_final %>%
summarise(across(where(is.numeric), ~ sum(.x, na.rm = TRUE))) %>%
pivot_longer(cols = everything(),
names_to = "variavel",
values_to = "soma")
# Mantém todas as não numéricas
# Identifica colunas numéricas com soma > 0
# Mantém apenas numéricas cuja soma > 0
bd_final <- bd_final |>
select(
where(~ !is.numeric(.x)),
where(~ is.numeric(.x) && sum(.x, na.rm = TRUE) > 0)
) |>
janitor::clean_names()
# Essa variável criada anteriormente era apenas para apoio
table(bd_final$homic_bin)
1
7735 # Vamos retirar
bd_final <- bd_final %>%
select(-homic_bin)
# Variáveis que identificam tipos de homicídio
bd_final <- bd_final %>%
mutate(
hq = ifelse(homicidio_qualificado == 1 | homicidio_qualificado_2 == 1, 1, 0),
hs = ifelse(homicidio_simples == 1, 1, 0),
fem = ifelse(feminicidio == 1, 1, 0)
)Trouxemos a tabela assuntos_wide_limpo e identificamos que algumas colunas estavam completamente zeradas. Isso ficou claro a partir da tabela de somas. Assim, removemos apenas as variáveis numéricas com soma igual a zero, mantendo todas as variáveis não numéricas.
Também excluímos a variável homic_bin, usada apenas como apoio na etapa anterior.
Por fim, criamos variáveis binárias para identificar três categorias principais de homicídio: homicídio qualificado, homicídio simples e feminicídio. É importante notar que essas categorias podem se sobrepor em alguns processos.
16.10.9 Análise da Movimentação Processual
Agora vamos analisar a movimentação processual. Para isso, precisamos extrair e organizar os dados de movimentação de cada processo. Vamos calcular o tempo decorrido entre cada movimentação e, em seguida, focar na análise do tempo até a baixa definitiva do processo.
movimento <- db_limpo |>
select(processo = numeroProcesso, movimentos) |>
unnest(movimentos) |>
janitor::clean_names() |>
select(-complementos_tabelados) |>
mutate(data_hora = parse_datetime(data_hora))
movimento <- movimento |>
arrange(processo, desc(data_hora)) |>
JurisMiner::tempo_movimentacao(data = data_hora)
movimento <- movimento |>
rename(movimento = nome,
cod_movimento = codigo
) 16.10.9.1 Tempo até a Baixa Definitiva
Vamos selecionar todos os processos para os quais conseguimos extrair a baixa definitiva. No código abaixo, buscamos manter apenas a primeira baixa de cada processo. Note que alguns processos apresentaram múltiplas baixas definitivas. Portanto, vamos considerar a última baixa definitiva que o processo teve.
# Tempo até a baixa definitiva
tempo_baixa <- movimento |>
filter(movimento == "Baixa Definitiva")
# número total de processos únicos
nrow(tempo_baixa %>%
distinct(processo, .keep_all = TRUE)) [1] 4633# Vamos analisar os processos duplicados
# Esse comando pega todas as linhas após a primeira ocorrência ou
# Pega todas as linhas antes da última ocorrência e verifica duplicação
t_baixa_dup <- tempo_baixa %>%
filter(duplicated(processo) | duplicated(processo, fromLast = TRUE))
## Vamos ver quantos processos duplicados temos:
# número de processos únicos que estão duplicados
unique(julgador_dup$processo) |> length() [1] 144## Deixamossomente o que tem a maior decorrência acumulada
tempo_baixa_unico <- tempo_baixa |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()Observe que agora temos um total de 4595 processos com baixa definitiva. Iniciamos com 8432 processos, e após a limpeza dos dados, restaram 7683 processos. Desses, conseguimos identificar a baixa definitiva em 4595 processos. Note uma redução significativa, representando um grupo específico de processos que chegaram à baixa definitiva.
Reflexão
Questão:
Os 4.595 representam bem a realidade dos processos de júri? Ao considerar esses processos estamos selecionando um grupo específico?
Juntando os Dados de Baixa com o Banco Final
Agora, vamos juntar com o nosso banco de dados, que criamos na parte anterior, e que contém assunto, classe e as demais variáveis binárias que geramos.
baixa_uni_comp <- tempo_baixa_unico |>
left_join(bd_final, by = c("processo" = "processo"))
# Verificar se criou uma coluna NA
sum(is.na(baixa_uni_comp$fem))[1] 0A junção não criou nenhuma coluna com valores NA, indicando que todos os processos com baixa definitiva foram corretamente integrados ao banco de dados final.
Análise Descritiva Geral
Primeiramente, vamos descrever ou realizar a análise descritiva do tempo até a baixa definitiva do processo. Neste momento, estamos considerando todos os 4.595 processos.
# Estatísticas descritivas para a variável decorrencia_acumulada
tempo_stats <- baixa_uni_comp %>%
summarise(
media = mean(decorrencia_acumulada, na.rm = TRUE),
mediana = median(decorrencia_acumulada, na.rm = TRUE),
desvio = sd(decorrencia_acumulada, na.rm = TRUE),
variancia = var(decorrencia_acumulada, na.rm = TRUE),
q1 = quantile(decorrencia_acumulada, 0.25, na.rm = TRUE),
q3 = quantile(decorrencia_acumulada, 0.75, na.rm = TRUE),
minimo = min(decorrencia_acumulada, na.rm = TRUE),
maximo = max(decorrencia_acumulada, na.rm = TRUE)
) |>
pivot_longer(
cols = everything(),
names_to = "Estatística",
values_to = "Valor"
)
# Tabela GT
tempo_stats %>%
gt() %>%
tab_header(
title = "Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva",
subtitle = "Variável: decorrencia_acumulada"
) %>%
fmt_number(
columns = Valor,
decimals = 2
)| Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva | |
|---|---|
| Variável: decorrencia_acumulada | |
| Estatística | Valor |
| media | 1,278.51 |
| mediana | 1,026.75 |
| desvio | 951.49 |
| variancia | 905,332.99 |
| q1 | 552.81 |
| q3 | 1,760.87 |
| minimo | 0.00 |
| maximo | 4,808.92 |
A média do tempo do processo até a baixa definitiva é de 1.280 dias, com desvio-padrão de 950 dias, mostrando grande variação nos tempos processuais. A mediana é de 1.030 dias, indicando que metade dos processos dura menos do que isso.
Distribuição dos tempos
- 25% dos processos são concluídos em até 554 dias.
- 50% (intervalo interquartil) estão entre 554 e 1.762 dias.
- 25% dos processos duram mais de 1.762 dias.
Visualmente
Vamos analisar também o tempo de forma gráfica, utilizando diferentes tipos de gráficos. Primeiro, apresentamos o gráfico conhecido como BoxPlot; em seguida, o gráfico chamado ViolinPlot. Depois, construímos os gráficos de densidade: inicialmente o histograma e, em seguida, a densidade contínua. Eles estão apresentados abaixo.
O Box Plot
O boxplot é um gráfico que traz muitas informações e pode ser visto como a distribuição de probabilidade dos dados.
Como visto acima, o gráfico representa a distribuição do tempo até a baixa definitiva e a sua concentração.
A caixa do boxplot mostra o intervalo interquartil: a parte inferior está em 554 dias, a mediana aparece ao redor de 1.030 dias e o terceiro quartil está em 1.761 dias. Esses valores compõem o interior da caixa, indicando onde se concentra 50% dos processos.
Observa-se também um número significativo de outliers, representados por pontos acima de aproximadamente 3.600 dias. Esses processos podem ser classificados como atípicos, pois apresentam tempos de duração muito superiores ao padrão da distribuição.
ggplot(baixa_uni_comp, aes(y = decorrencia_acumulada)) +
geom_boxplot(fill = "#7185cc", color = "#c2986f", alpha=0.7, # Linhas tracejadas no boxplot
outlier.shape = 16, outlier.color = "red", outlier.size = 3) + # Boxplot com preenchimento azul e bordas pretas
labs(
title = "Boxplot do Tempo do Processo até Baixa Definitiva", # Título do gráfico
x = "", # Sem rótulo no eixo x
y = "Tempo" # Rótulo do eixo y
) +
coord_flip() + # Inverte os eixos para horizontalidade
theme_bw() + # Tema limpo e moderno
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"), # Centraliza e estiliza o título
axis.text.y = element_text(size = 10), # Ajusta o tamanho do texto no eixo y
axis.title.y = element_text(size = 12) # Ajusta o tamanho do rótulo do eixo y
)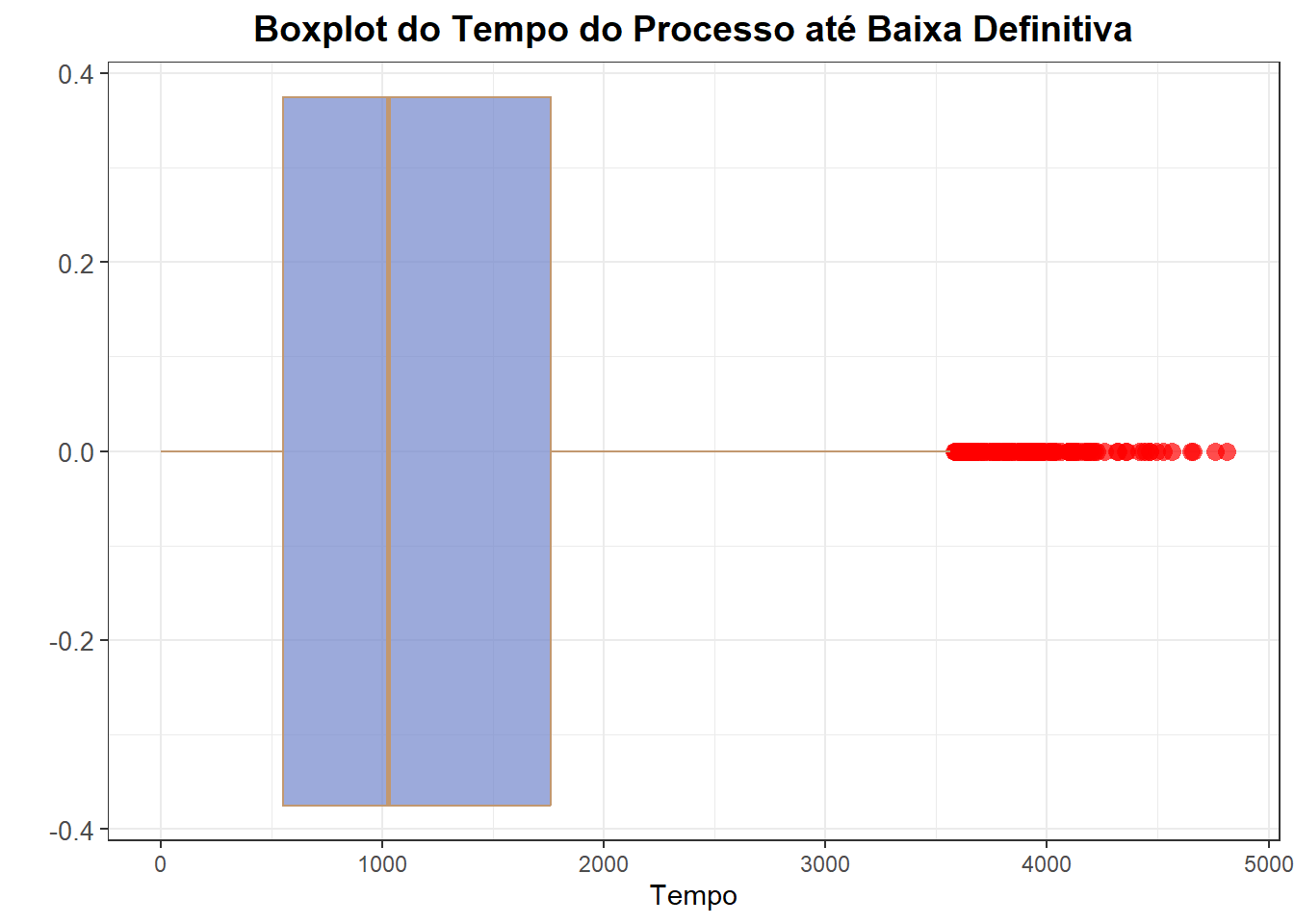
O BOXPLOT
O box ou caixa contém 50% dos dados. O limite superior indica o percentil de 75% (Q3) e o limite inferior indica o percentil de 25% (Q1). A linha que corta o box indica a mediana, ou seja, Q2. Os bigodes são calculados com base na distância interquantílica, ou seja,
Limite inferior: Q1-1,5(Q3-Q1)
Limite superior:Q3+1,5(Q3-Q1)
Dados fora desses limites são classificados como suspeitos de serem outliers. Podemos observar a assimetria dos dados quando a mediana não está no meio da caixa, indicando maior densidade na menor distância entre os quartis Q1 ou Q3 e a mediana Q2.
Gráfico de Densidade
Visualizar a distribuição empírica dos dados fornece uma grande quantidade de informação. Um gráfico básico em análise descritiva é o histograma, o qual fornece a distribuição de probabilidade empírica dos dados em um formato de barras. O histograma mostra a frequência de processos em cada faixa de duração até a baixa definitiva. A altura de cada barra indica quantos processos estão naquela faixa de dias.
ggplot(baixa_uni_comp, aes(x = decorrencia_acumulada)) +
geom_histogram(bins = 30, fill = "#7185cc", color = "white", alpha = 0.7) +
geom_vline(aes(xintercept = mean(decorrencia_acumulada)), color = "#c2986f", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 1400, y = 300, vjust = -0.5, label = "Média", color = "#c2986f", fontface = "bold", size = 4) +
geom_vline(aes(xintercept = median(decorrencia_acumulada)), color = "#c77878ff", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 900, y = 400, vjust = -0.5, label = "Mediana", color = "#c77878ff", fontface = "bold", size = 4) +
labs(
x = "Tempo do Processo",
y = "Frequência",
title = "Histograma do Tempo do Processo até Baixa Definitiva"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10))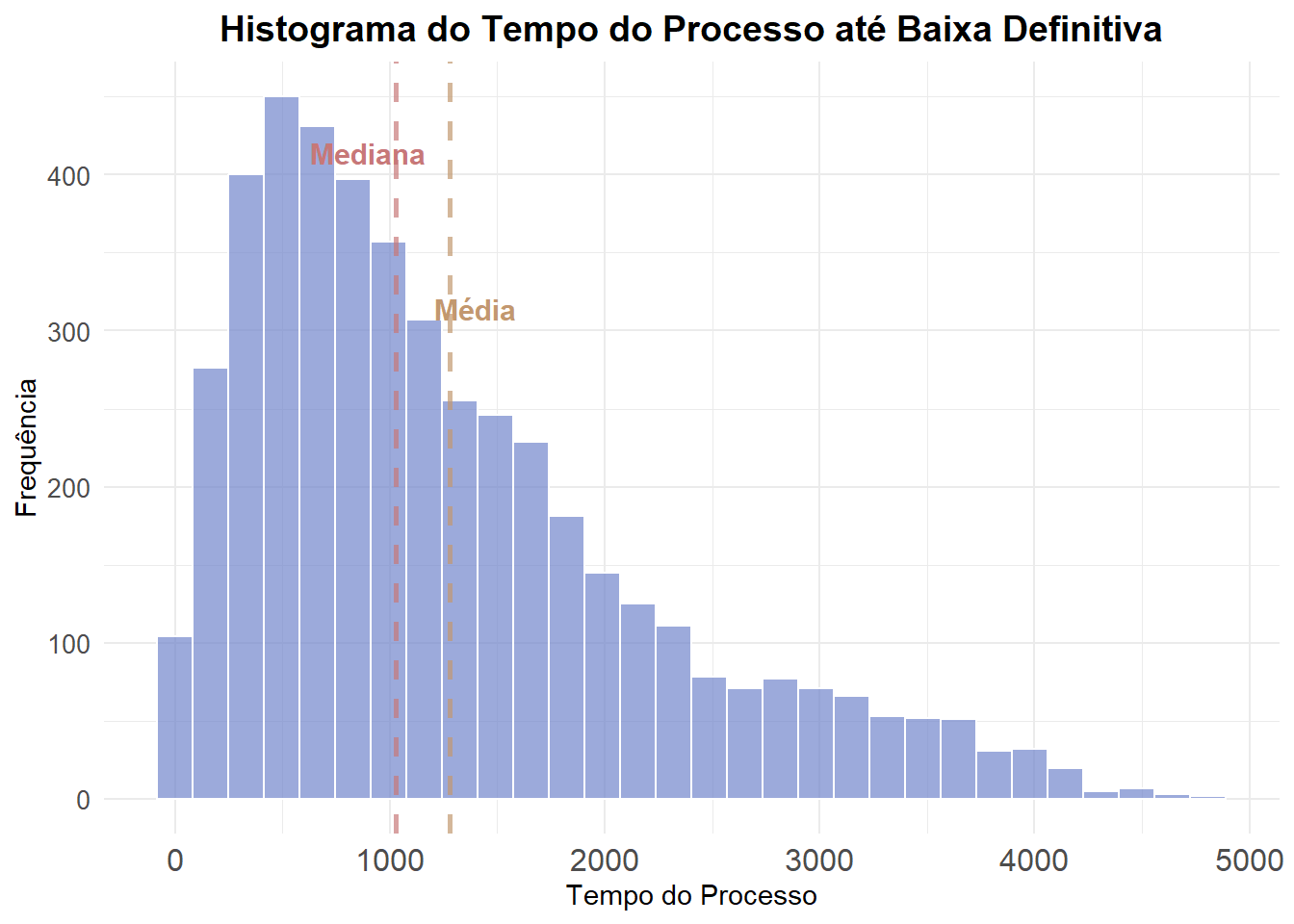
Observa-se que há um número relevante de processos com poucos dias até a baixa definitiva. Pfecisamos decidir o que fazer com esses processos. Devemos excluí-los?
A distribuição é assimétrica à direita, com uma cauda longa, o que significa que existe um grupo menor de processos que dura muito mais tempo, esses valores elevados puxam a média para cima.
A maior concentração de processos ocorre entre 800 e 900 dias, e aproximadamente metade dos processos é concluída em até 1.000 dias. A partir desse ponto, a frequência diminui gradualmente, até alcançar valores próximos de 4.000 dias, onde a cauda longa se torna evidente.
Uma outra maneira de visualizar os dados é utilizando uma distribuição continua e não mais a discreta. Para isso, utiliza-se a densidade de Kernel para visualização da distribuição de probabilidade da taxa de feminicídio. Vejamos:
ggplot(baixa_uni_comp, aes(x = decorrencia_acumulada)) +
geom_density(fill = "#7185cc", alpha = 0.4, color = "#7185cc", linewidth = 1) +
geom_vline(aes(xintercept = mean(decorrencia_acumulada)), color = "#c2986f", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 1400, y = 0.00005, vjust = -0.5, label = "Média", color = "#c2986f", fontface = "bold", size = 4) +
geom_vline(aes(xintercept = median(decorrencia_acumulada)), color = "#c77878ff", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 900, y = 0.00005, vjust = -0.5, label = "Mediana", color = "#c77878ff", fontface = "bold", size = 4) +
labs(
x = "Tempo do Processo",
y = "Frequência",
title = "Histograma do Tempo do Processo até Baixa Definitiva"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10))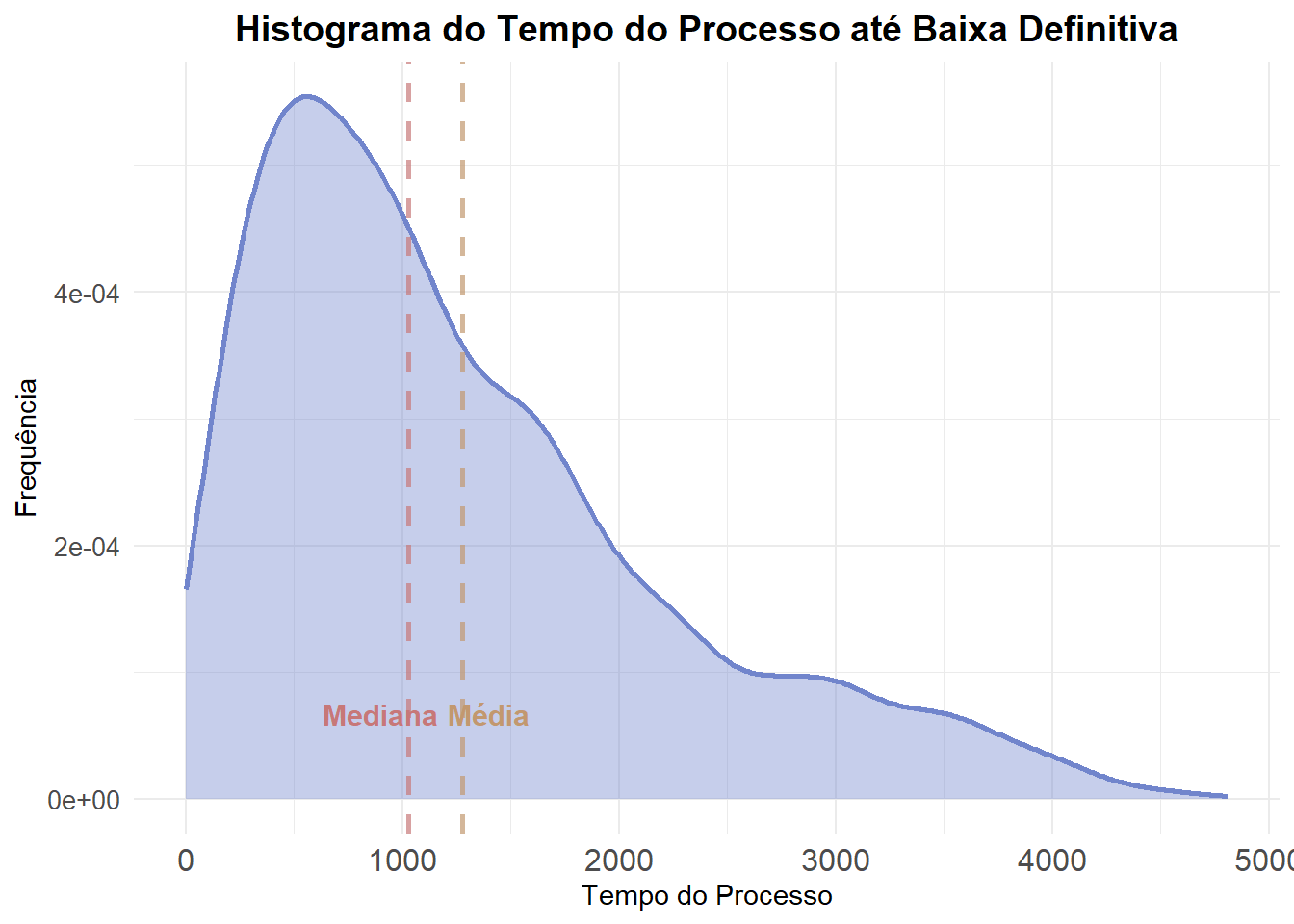
Análise por Órgão Julgador
Vamos analisar agora por órgão julgador, os 5 maiores em relação aos demais.
# Estatísticas descritivas estratificadas por volume_top5
tempo_stats_grupo <- baixa_uni_comp %>%
group_by(volume_top5) %>%
summarise(
media = mean(decorrencia_acumulada, na.rm = TRUE),
mediana = median(decorrencia_acumulada, na.rm = TRUE),
desvio = sd(decorrencia_acumulada, na.rm = TRUE),
variancia = var(decorrencia_acumulada, na.rm = TRUE),
q1 = quantile(decorrencia_acumulada, 0.25, na.rm = TRUE),
q3 = quantile(decorrencia_acumulada, 0.75, na.rm = TRUE),
minimo = min(decorrencia_acumulada, na.rm = TRUE),
maximo = max(decorrencia_acumulada, na.rm = TRUE)
) %>%
pivot_longer(
cols = -volume_top5,
names_to = "Estatística",
values_to = "Valor"
)%>%
pivot_wider(
names_from = volume_top5,
values_from = Valor
)
# Tabela GT
tempo_stats_grupo %>%
gt(groupname_col = "volume_top5") %>%
tab_header(
title = "Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva",
subtitle = "Estratificadas 5 maiores órgãos julgadores )"
) %>%
fmt_number(
columns = where(is.numeric),
decimals = 2
) %>%
cols_label(
Estatística = "Estatística",
`0` = "Demais",
`1` = "Top 5"
)| Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva | ||
|---|---|---|
| Estratificadas 5 maiores órgãos julgadores ) | ||
| Estatística | Demais | Top 5 |
| media | 1,323.58 | 1,192.65 |
| mediana | 1,032.56 | 1,014.74 |
| desvio | 1,016.59 | 806.57 |
| variancia | 1,033,446.72 | 650,561.17 |
| q1 | 529.45 | 595.42 |
| q3 | 1,839.32 | 1,640.99 |
| minimo | 0.00 | 0.33 |
| maximo | 4,808.92 | 4,414.10 |
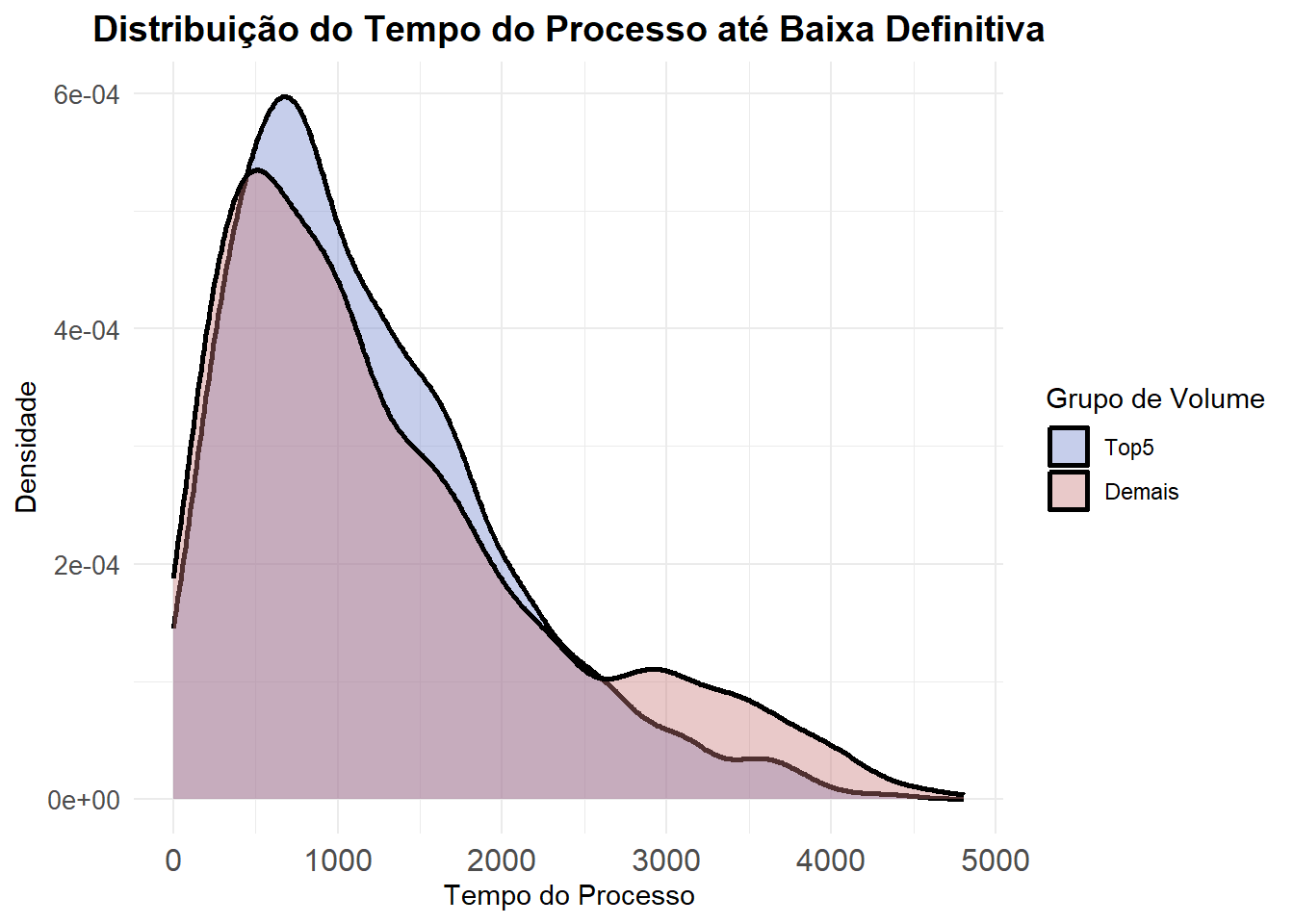
Observamos que as cinco maiores varas apresentam uma média de 1.194 dias até a baixa definitiva, enquanto as demais varas possuem uma média de 1.325 dias. Há, portanto, uma diferença entre as médias dos dois grupos.
Também se verifica diferença na dispersão: nas cinco maiores varas, o desvio-padrão é de 802 dias, ao passo que nas demais varas ele chega a 1.015 dias. Isso indica que, além de terem um tempo médio menor, as cinco maiores varas apresentam uma duração dos processos mais concentrada e com menor variabilidade em comparação às demais comarcas.
Vejamos a distribuição graficamente:
# Garantir que seja fator
baixa_uni_comp$volume_top5_factor <- factor(baixa_uni_comp$volume_top5, levels = c(1, 0), labels = c("Top5", "Demais"))
ggplot(baixa_uni_comp, aes(x = decorrencia_acumulada, fill = volume_top5_factor, group = volume_top5_factor)) +
geom_density(alpha = 0.4, linewidth = 1) +
labs(
x = "Tempo do Processo",
y = "Densidade",
title = "Distribuição do Tempo do Processo até Baixa Definitiva"
) +
scale_fill_manual(
name = "Grupo de Volume",
values = c("Top5" = "#7185cc", "Demais" = "#c77878ff") # cores específicas
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10)
)
Para avaliar se a diferença entre as médias dos dois grupos é estatisticamente significativa, realizamos um teste t de diferença de médias. O resultado foi significativo, indicando que as médias dos dois grupos são, de fato, diferentes.
Em termos práticos, isso significa que, em média, as cinco varas com maior volume de processos apresentam um tempo médio de tramitação menor do que o observado nas demais varas.
t.test(
decorrencia_acumulada ~ volume_top5,
data = baixa_uni_comp,
var.equal = FALSE) # teste de Welch (padrão e mais seguro)
Welch Two Sample t-test
data: decorrencia_acumulada by volume_top5
t = 4.7872, df = 3927.7, p-value = 1.753e-06
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
77.31067 184.55563
sample estimates:
mean in group 0 mean in group 1
1323.583 1192.650 Vamos agora analisar por vara especializada versus não especializada.
# Estatísticas descritivas estratificadas por vara especializada
tempo_stats_grupo_espec <- baixa_uni_comp %>%
group_by(vara_espec) %>%
summarise(
media = mean(decorrencia_acumulada, na.rm = TRUE),
mediana = median(decorrencia_acumulada, na.rm = TRUE),
desvio = sd(decorrencia_acumulada, na.rm = TRUE),
variancia = var(decorrencia_acumulada, na.rm = TRUE),
q1 = quantile(decorrencia_acumulada, 0.25, na.rm = TRUE),
q3 = quantile(decorrencia_acumulada, 0.75, na.rm = TRUE),
minimo = min(decorrencia_acumulada, na.rm = TRUE),
maximo = max(decorrencia_acumulada, na.rm = TRUE)
) %>%
pivot_longer(
cols = -vara_espec,
names_to = "Estatística",
values_to = "Valor"
)%>%
pivot_wider(
names_from = vara_espec,
values_from = Valor
)
# Tabela GT
tempo_stats_grupo_espec %>%
gt(groupname_col = "volume_top5") %>%
tab_header(
title = "Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva",
subtitle = "Estratificadas Especializada (1) e Demais (0)"
) %>%
fmt_number(
columns = where(is.numeric),
decimals = 2
) %>%
cols_label(
Estatística = "Estatística",
`0` = "Demais",
`1` = "Especializada"
)| Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva | ||
|---|---|---|
| Estratificadas Especializada (1) e Demais (0) | ||
| Estatística | Demais | Especializada |
| media | 1,299.61 | 1,140.40 |
| mediana | 1,053.10 | 860.15 |
| desvio | 947.31 | 967.88 |
| variancia | 897,400.40 | 936,782.63 |
| q1 | 578.03 | 456.03 |
| q3 | 1,778.93 | 1,609.66 |
| minimo | 0.00 | 0.02 |
| maximo | 4,808.92 | 4,660.03 |
Neste caso, observamos uma diferença ainda maior entre os grupos: enquanto as demais varas apresentam tempo médio de 1.302 dias, as varas especializadas têm média de 1.138 dias.
t.test(
decorrencia_acumulada ~ vara_espec,
data = baixa_uni_comp,
var.equal = FALSE) # teste de Welch (padrão e mais seguro)
Welch Two Sample t-test
data: decorrencia_acumulada by vara_espec
t = 3.8068, df = 802.93, p-value = 0.0001515
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
77.11211 241.29481
sample estimates:
mean in group 0 mean in group 1
1299.606 1140.402 O teste de diferença de média mostra que os processos tramitam mais rapidamente nas varas especializadas em relação as demais e é estatisticamente significativo a 1%.
Vamos agora repetir a mesma análise, mas classificando os processos por assunto. Começaremos examinando os casos de homicídio qualificado, comparando-os com os demais processos.
O objetivo é verificar se os processos de homicídio qualificado apresentam um padrão distinto de duração.
# Estatísticas descritivas estratificadas por Homicídio Qualificado
tempo_stats_grupo1 <- baixa_uni_comp %>%
group_by(hq) %>%
summarise(
media = mean(decorrencia_acumulada, na.rm = TRUE),
mediana = median(decorrencia_acumulada, na.rm = TRUE),
desvio = sd(decorrencia_acumulada, na.rm = TRUE),
variancia = var(decorrencia_acumulada, na.rm = TRUE),
q1 = quantile(decorrencia_acumulada, 0.25, na.rm = TRUE),
q3 = quantile(decorrencia_acumulada, 0.75, na.rm = TRUE),
minimo = min(decorrencia_acumulada, na.rm = TRUE),
maximo = max(decorrencia_acumulada, na.rm = TRUE)
) %>%
pivot_longer(
cols = -hq,
names_to = "Estatística",
values_to = "Valor"
)%>%
pivot_wider(
names_from = hq,
values_from = Valor
)
# Tabela GT
tempo_stats_grupo1 %>%
gt(groupname_col = "volume_top5") %>%
tab_header(
title = "Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva",
subtitle = "Estratificadas Homicídio Qualificado (1) e Demais (0)"
) %>%
fmt_number(
columns = where(is.numeric),
decimals = 2
) %>%
cols_label(
Estatística = "Estatística",
`0` = "Demais",
`1` = "Homic Qualificado"
)| Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva | ||
|---|---|---|
| Estratificadas Homicídio Qualificado (1) e Demais (0) | ||
| Estatística | Demais | Homic Qualificado |
| media | 1,312.37 | 1,264.99 |
| mediana | 1,028.42 | 1,025.19 |
| desvio | 1,021.29 | 921.96 |
| variancia | 1,043,026.56 | 850,013.08 |
| q1 | 528.80 | 563.88 |
| q3 | 1,836.54 | 1,725.29 |
| minimo | 0.03 | 0.00 |
| maximo | 4,808.92 | 4,759.90 |
Observamos agora que as médias dos dois grupos são mais próximas: os processos de homicídio qualificado apresentam tempo médio de 1.264 dias, enquanto os demais processos têm média de 1.319 dias. Da mesma forma, os desvios-padrão também são semelhantes: cerca de 921 dias para homicídio qualificado e 1.017 dias para os demais assuntos.
Portanto, ao contrário do que vimos no caso das varas, não há uma diferença tão acentuada.
t.test(
decorrencia_acumulada ~ hq,
data = baixa_uni_comp,
var.equal = FALSE) # teste de Welch (padrão e mais seguro)
Welch Two Sample t-test
data: decorrencia_acumulada by hq
t = 1.4652, df = 2226.5, p-value = 0.143
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-16.0330 110.7958
sample estimates:
mean in group 0 mean in group 1
1312.368 1264.987 O teste de média s indicou que a diferença entre os dois grupos não é estatisticamente significativa a 5%. Isso sugere que, em termos práticos, o tempo médio de tramitação dos processos de homicídio qualificado não difere significativamente dos demais processos.
Vejamos agora os processos de feminicídio, comparando-os com os demais processos. O objetivo é verificar se os processos de feminicídio apresentam um padrão distinto de duração em relação aos outros tipos de homicídio.
# Estatísticas descritivas estratificadas por Feminicídio
tempo_stats_grupo2 <- baixa_uni_comp %>%
group_by(fem) %>%
summarise(
media = mean(decorrencia_acumulada, na.rm = TRUE),
mediana = median(decorrencia_acumulada, na.rm = TRUE),
desvio = sd(decorrencia_acumulada, na.rm = TRUE),
variancia = var(decorrencia_acumulada, na.rm = TRUE),
q1 = quantile(decorrencia_acumulada, 0.25, na.rm = TRUE),
q3 = quantile(decorrencia_acumulada, 0.75, na.rm = TRUE),
minimo = min(decorrencia_acumulada, na.rm = TRUE),
maximo = max(decorrencia_acumulada, na.rm = TRUE)
) %>%
pivot_longer(
cols = -fem,
names_to = "Estatística",
values_to = "Valor"
)%>%
pivot_wider(
names_from = fem,
values_from = Valor
)
# Tabela GT
tempo_stats_grupo2 %>%
gt(groupname_col = "volume_top5") %>%
tab_header(
title = "Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva",
subtitle = "Estratificadas Feminicídio (1) e Demais (0)"
) %>%
fmt_number(
columns = where(is.numeric),
decimals = 2
) %>%
cols_label(
Estatística = "Estatística",
`0` = "Demais",
`1` = "Feminicídio"
)| Estatísticas Descritivas — Tempo do Processo até Baixa Definitiva | ||
|---|---|---|
| Estratificadas Feminicídio (1) e Demais (0) | ||
| Estatística | Demais | Feminicídio |
| media | 1,283.80 | 1,135.06 |
| mediana | 1,034.71 | 837.78 |
| desvio | 955.92 | 811.98 |
| variancia | 913,780.13 | 659,305.10 |
| q1 | 553.48 | 531.84 |
| q3 | 1,764.05 | 1,643.99 |
| minimo | 0.00 | 1.51 |
| maximo | 4,808.92 | 4,414.10 |
t.test(
decorrencia_acumulada ~ fem,
data = baixa_uni_comp,
var.equal = FALSE) # teste de Welch (padrão e mais seguro)
Welch Two Sample t-test
data: decorrencia_acumulada by fem
t = 2.2951, df = 181.2, p-value = 0.02288
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
20.86379 276.62156
sample estimates:
mean in group 0 mean in group 1
1283.804 1135.062 Observamos que os processos classificados como feminicídio apresentam uma média de duração menor do que aqueles não classificados dessa forma. A diferença entre as médias é de aproximadamente 150 dias, e é estatisticamente significativa a 5%
Vamos tentar analisar por meio de um modelo linear multivariado, que considera todas as variáveis anteriores.
lm_model <- lm(decorrencia_acumulada ~ volume_top5 + vara_espec + hq + fem, data = baixa_uni_comp)
modelsummary(
lm_model,
output = "gt",
statistic = c("std.error", "p.value"),
shape = term ~ statistic,
fmt=2,
gof_map = tribble(
~raw, ~clean, ~fmt,
"adj.r.squared","R² ajustado", 3,
"nobs", "N. de observações", 0,
"fstatistic", "Estatística F", 3
),
stars = TRUE,
title = "Modelo de Regressão Linear",
notes = "S.E.: Erro padrão."
)
(1)
|
|||
|---|---|---|---|
| Est. | S.E. | p | |
| (Intercept) | 1409.94*** | 29.32 | <0.01 |
| volume_top5 | -171.91*** | 30.60 | <0.01 |
| vara_espec | -234.12*** | 42.79 | <0.01 |
| hq | -49.72 | 31.11 | 0.11 |
| fem | -159.88* | 75.64 | 0.03 |
| R² ajustado | 0.011 | ||
| N. de observações | 4633 | ||
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||
| S.E.: Erro padrão. | |||
Observe-se que o intercepto do nosso modelo é de 1.418 dias. Esse valor representa o tempo médio dos processos que não estão entre as cinco varas de maior volume, não tramitam em varas especializadas e não são classificados como homicídio qualificado ou feminicídio. Ou seja, é o valor esperado quando todas as demais variáveis do modelo são iguais a zero. Esta é a interpretação básica do intercepto.
Em relação a esse grupo de referência, observamos reduções importantes no tempo médio do processo:
- Nas cinco varas de maior volume, o tempo médio é cerca de 171 dias menor do que o valor do intercepto (1.418 dias).
- Nas varas especializadas, a redução é ainda maior, aproximadamente 238 dias a menos em relação ao intercepto.
- Para os processos classificados como feminicídio, há também uma diminuição média de 164 dias.
Esses valores indicam quanto cada característica reduz o tempo esperado em comparação com o grupo base definido pelo intercepto.
16.10.9.2 Analisando as Fases do Processo de Júri
A estratégia de análise será a seguinte:
flowchart LR A[Distribuição] --> B[Recebimento da Denúncia] B --> C[Aud. Instrução e Julgamento] C --> D[Dec. Pronúncia] D --> E[Seç. Trib. do Júri]
- Distribuição:
- Recebimento da Denúncia: 391
- Audiência de Instrução e Julgamento: 12750
- Decisão de Pronúncia: 10953
- Seção do Tribunal do Júri: 313
Montando os bancos de dados para cada fase do processo
Vamos montar os bancos e organizar um banco único para cada fase do processo de júri.
# Montar as bases e selecionar apenas as variáveis desejadas em cada base
# Tempo até a denuncia
t_denuncia <- movimento |>
filter(cod_movimento == "391")
## Deixamos somente a primeira denuncia
t_denuncia_unico <- t_denuncia |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_denuncia_unico <- t_denuncia_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_denuncia=cod_movimento,
deco_denuncia = decorrencia_acumulada,
data_denuncia = data_hora)
# Tempo até a Instrução e Julgamento
t_int_julg <- movimento |>
filter(cod_movimento == "12750")
## Deixamos somente a primeira instrução e julgamento
t_int_julg_unico <- t_int_julg |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_int_julg_unico <- t_int_julg_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_instr=cod_movimento,
deco_intjulg = decorrencia_acumulada,
data_intjulg = data_hora)
# Tempo até a pronuncia
t_pronun <- movimento |>
filter(cod_movimento == "10953")
## Deixamos somente a primeira denuncia
t_pronun_unico <- t_pronun |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_pronun_unico <- t_pronun_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_pronun=cod_movimento,
deco_pronun = decorrencia_acumulada,
data_pronun = data_hora)
# Tempo até a juri
t_juri <- movimento |>
filter(cod_movimento == "313")
## Deixamos somente a primeira denuncia
t_juri_unico <- t_juri |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_juri_unico <- t_juri_unico %>%
distinct(processo, .keep_all = TRUE)
t_juri_unico <- t_juri_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_juri=cod_movimento,
deco_juri = decorrencia_acumulada,
data_juri = data_hora)
tempo_baixa_unico <- tempo_baixa_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_baixa=cod_movimento,
deco_baixa = decorrencia_acumulada,
data_baixa = data_hora)
mov_final <- bd_final |>
left_join(t_denuncia_unico, by ="processo")|>
left_join(t_int_julg_unico, by = "processo") |>
left_join(t_pronun_unico, by = "processo") |>
left_join(t_juri_unico, by = "processo") |>
left_join(tempo_baixa_unico, by ="processo")
mov_final <- mov_final |>
drop_na(deco_intjulg, deco_baixa, deco_juri, deco_pronun, deco_denuncia)Agora que juntamos todas as movimentações e eliminamos os casos com valores ausentes e chegamos a um total de 1.034 processos.
Partimos originalmente de 8.432 processos no banco básico. Portanto, houve uma redução substancial da base analítica, com a exclusão de aproximadamente 7.400 processos.
Essa redução levanta uma questão central para a análise:
os 1.034 processos restantes são representativos do conjunto original ou formam um grupo com características muito diferentes?
Para evitar viés de seleção, vamos seguir olhando cada variável individualmente e comparando as estatísticas descritivas de cada fase do processo.
# 1. Função para gerar estatísticas descritivas
make_stats <- function(x) {
tibble::tibble(
Estatística = c(
"media", "mediana", "desvio", "variancia",
"q1", "q3", "minimo", "maximo"
),
Valor = c(
mean(x, na.rm = TRUE),
median(x, na.rm = TRUE),
sd(x, na.rm = TRUE),
var(x, na.rm = TRUE),
quantile(x, 0.25, na.rm = TRUE),
quantile(x, 0.75, na.rm = TRUE),
min(x, na.rm = TRUE),
max(x, na.rm = TRUE)
)
)
}
# Tempo até a denuncia
t_denuncia <- movimento |>
filter(cod_movimento == "391")
t_denuncia_unico <- t_denuncia |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_denuncia_unico <- t_denuncia_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_denuncia=cod_movimento,
deco_denuncia = decorrencia_acumulada,
data_denuncia = data_hora)
# Tempo até a Instrução e Julgamento
t_int_julg <- movimento |>
filter(cod_movimento == "12750")
t_int_julg_unico <- t_int_julg |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_int_julg_unico <- t_int_julg_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_instr=cod_movimento,
deco_intjulg = decorrencia_acumulada,
data_intjulg = data_hora)
# Tempo até a pronuncia
t_pronun <- movimento |>
filter(cod_movimento == "10953")
t_pronun_unico <- t_pronun |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_pronun_unico <- t_pronun_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_pronun=cod_movimento,
deco_pronun = decorrencia_acumulada,
data_pronun = data_hora)
# Tempo até a juri
t_juri <- movimento |>
filter(cod_movimento == "313")
t_juri_unico <- t_juri |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
ungroup()
t_juri_unico <- t_juri_unico %>%
distinct(processo, .keep_all = TRUE)
t_juri_unico <- t_juri_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_juri=cod_movimento,
deco_juri = decorrencia_acumulada,
data_juri = data_hora)
tempo_baixa_unico <- tempo_baixa_unico |>
select(processo, cod_movimento, decorrencia_acumulada, data_hora) |>
rename(cod_baixa=cod_movimento,
deco_baixa = decorrencia_acumulada,
data_baixa = data_hora)
# 2. Gerar estatísticas para cada banco
stats_denuncia <- make_stats(t_denuncia_unico$deco_denuncia)
stats_intjulg <- make_stats(t_int_julg_unico$deco_intjulg)
stats_pronun <- make_stats(t_pronun_unico$deco_pronun)
stats_juri <- make_stats( t_juri_unico$deco_juri)
stats_baixa <- make_stats(tempo_baixa_unico$deco_baixa)
# 3. Juntar tudo em uma única tabela
stats_baixa <- stats_baixa %>% rename(Baixa = Valor)
stats_intjulg <- stats_intjulg %>% rename(Instr_Julg = Valor)
stats_pronun <- stats_pronun %>% rename(Pronuncia = Valor)
stats_juri <- stats_juri %>% rename(Juri = Valor)
stats_denuncia <- stats_denuncia %>% rename(Denuncia = Valor)
all_stats <- stats_denuncia %>%
left_join(stats_intjulg, by = "Estatística") %>%
left_join(stats_pronun, by = "Estatística") %>%
left_join(stats_juri, by = "Estatística") %>%
left_join(stats_baixa, by = "Estatística")
# 4. Gerar tabela final
all_stats %>%
gt() %>%
fmt_number(
columns = where(is.numeric), # aplica a todas as colunas numéricas
decimals = 2
) %>%
tab_header(
title = "Estatísticas Descritivas — Todas as Fases do Processo"
)| Estatísticas Descritivas — Todas as Fases do Processo | |||||
|---|---|---|---|---|---|
| Estatística | Denuncia | Instr_Julg | Pronuncia | Juri | Baixa |
| media | 32.40 | 491.02 | 678.65 | 1,016.68 | 1,278.51 |
| mediana | 2.99 | 161.77 | 346.08 | 730.96 | 1,026.75 |
| desvio | 169.50 | 760.26 | 787.45 | 884.97 | 951.49 |
| variancia | 28,731.29 | 577,997.75 | 620,083.62 | 783,173.29 | 905,332.99 |
| q1 | 0.88 | 65.28 | 176.15 | 368.87 | 552.81 |
| q3 | 9.85 | 559.70 | 882.12 | 1,396.07 | 1,760.87 |
| minimo | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| maximo | 3,377.73 | 4,668.86 | 4,434.01 | 4,784.91 | 4,808.92 |
Nessa tabela tem-se uma visão geral das estatísticas descritivas para cada fase do processo. Observa-se que o tempo médio da distribuição até o Recebimento da Denúncia é de 32,51 dias. Já o tempo médio da distribuição até a Audiência de Instrução e Julgamento é de 490,23 dias.
16.10.9.3 Da distribuição até o Recebimento da Denúncia
Primeiro vamos analisar o tempo entre a distribuição do processo e o recebimento da denúncia. Graficamente tem-se:
t_denuncia_unico <- t_denuncia_unico
ggplot(t_denuncia_unico, aes(x = deco_denuncia)) +
geom_histogram(bins = 3000, fill = "#7185cc", color = "white", alpha = 0.7) +
geom_vline(aes(xintercept = mean(deco_denuncia)), color = "#c2986f", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 37, y = 500, vjust = -0.5, label = "Média", color = "#c2986f", fontface = "bold", size = 4) +
geom_vline(aes(xintercept = median(deco_denuncia)), color = "#c77878ff", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 7, y = 500, vjust = -0.5, label = "Mediana", color = "#c77878ff", fontface = "bold", size = 4) +
labs(
x = "Tempo em dias (até 50 dias)",
y = "Frequência",
title = "Histograma do Tempo da Distribuição até a Denúncia"
) +
coord_cartesian(xlim = c(0, 50)) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10))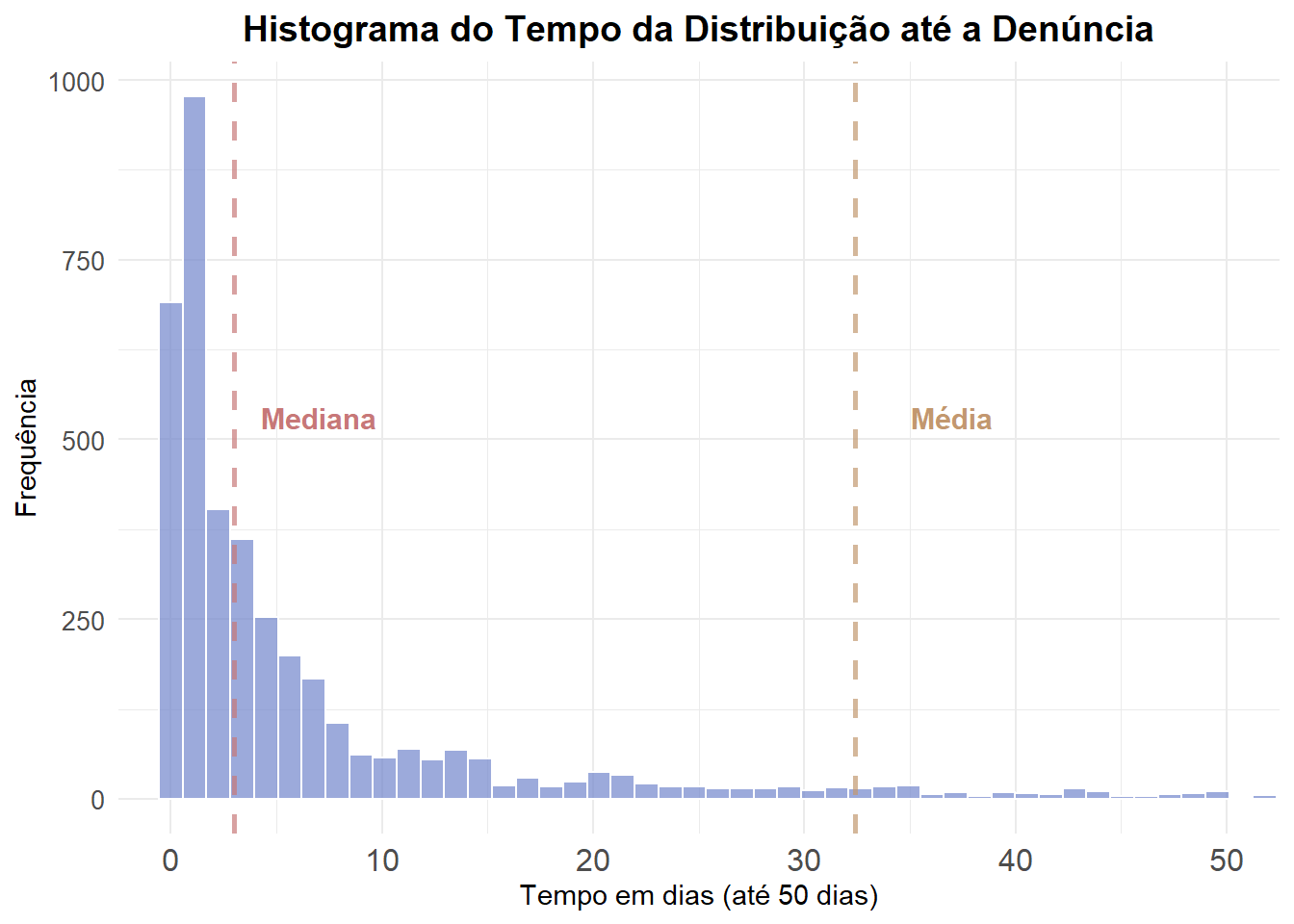
Observa-se que 50% dos processos duram menos de 3 dias entre a distribuição e o recebimento da denúncia. Entretanto, a média é bem maior, em torno de 32 dias.
Essa diferença indica que existem processos com duração muito longa, alguns com mais de 100 dias, que puxam a média para cima. Ou seja, a distribuição é assimétrica, com uma cauda longa à direita.
# Contar quantos processos têm soma maior que 30 dias
t_denuncia_unico %>%
filter(deco_denuncia > 30) %>%
summarise(n = n(),
percentual = n() / nrow(t_denuncia_unico) * 100,
media= mean(deco_denuncia))# A tibble: 1 × 3
n percentual media
<int> <dbl> <dbl>
1 499 11.6 244.Observa-se que aproximadamente 12% dos processos levam mais de 30 dias entre a distribuição e o recebimento da denúncia e possuem média de 245 dias nesse grupo.
Para entender melhor essa diferença, iremos investigar os atos ordinatórios e outros atos, pois eles podem estar contribuindo significativamente para o aumento do tempo entre distribuição e denúncia.
Movimentação até Recebimento da Denúncia
Vamos analisar a movimentação do processo desde a distribuição até o recebimento da denúncia. Vamos criar um banco específico para essa análise.
# 1. Identificar o tempo da denúncia para cada processo
tempo_denuncia <- movimento |>
filter(cod_movimento == "391") |>
group_by(processo) |>
slice_min(decorrencia_acumulada, n = 1) |>
select(processo, deco_denuncia=decorrencia_acumulada)
# 2. Selecionar todos os atos até a denúncia
atos_ate_denuncia <- movimento %>%
left_join(tempo_denuncia, by = "processo") %>%
filter(decorrencia_acumulada <= deco_denuncia) Criamos um banco que possui todos os movimentos processuais desde a distribuição até o recebimento da denúncia. Agora, vamos analisar a frequência dos movimentos processuais.
freq_movimento <- atos_ate_denuncia %>%
count(movimento, sort = TRUE) # conta por descrição do movimento
freq_movimento %>%
gt() %>%
tab_header(
title = "Frequência de Movimentos até a Denúncia"
) %>%
fmt_number(
columns = "n",
decimals = 0
) %>%
cols_label(
movimento = "Movimento",
n = "Frequência"
)| Frequência de Movimentos até a Denúncia | |
|---|---|
| Movimento | Frequência |
| Conclusão | 4,688 |
| Distribuição | 4,367 |
| Denúncia | 4,313 |
| Ato ordinatório | 4,014 |
| Remessa | 1,802 |
| Documento | 934 |
| Protocolo de Petição | 886 |
| Expedida/certificada | 575 |
| Expedição de documento | 445 |
| Confirmada | 432 |
| Mero expediente | 360 |
| Mandado | 273 |
| Mudança de Assunto Processual | 260 |
| Recebimento | 245 |
| Mudança de Parte | 169 |
| Expedida/Certificada | 161 |
| Mudança de Classe Processual | 144 |
| Redistribuição | 99 |
| Decurso de Prazo | 84 |
| Movimentação processual | 67 |
| Retificação de Classe Processual | 44 |
| Inclusão no Juízo 100% Digital | 42 |
| Réu revel citado por edital | 34 |
| Queixa | 33 |
| de Instrução e Julgamento | 20 |
| Outras Decisões | 15 |
| Publicação | 15 |
| Levantamento da Suspensão ou Dessobrestamento | 11 |
| deferimento | 11 |
| Incompetência | 8 |
| Aditamento da denúncia | 6 |
| Desarquivamento | 6 |
| Disponibilização no Diário da Justiça Eletrônico | 6 |
| Ofício | 6 |
| Por decisão judicial | 6 |
| Suspeição | 6 |
| Impedimento ou Suspeição | 5 |
| Cumprimento de Levantamento da Suspensão | 4 |
| Incidente de Insanidade Mental | 4 |
| Registro Processual | 4 |
| Sessão do Tribunal do Júri | 4 |
| Audiência | 3 |
| Com efeito suspensivo | 3 |
| Liberdade provisória | 3 |
| Sem efeito suspensivo | 3 |
| de Custódia | 3 |
| Cadastramento | 2 |
| Decisão anterior | 2 |
| Depósito de Bens/Dinheiro | 2 |
| Julgamento em Diligência | 2 |
| Requisição de Informações | 2 |
| Revogação da Suspensão do Processo | 2 |
| Suspensão ou Sobrestamento | 2 |
| de Instrução | 2 |
| Baixa Definitiva | 1 |
| Comparecimento do Réu/Apenado | 1 |
| Desmembramento de Feitos | 1 |
| Em Secretaria | 1 |
| Impedimento | 1 |
| Improcedência | 1 |
| Indeferimento | 1 |
| Liberdade Provisória | 1 |
| Liminar | 1 |
| Morte do agente | 1 |
| Prisão | 1 |
| Prisão em flagrante | 1 |
| Procedência | 1 |
| Pronúncia | 1 |
| Suspensão Condicional do Processo | 1 |
| de Interrogatório | 1 |
ATOS ORDINATÓRIOS
E abaixo vamos somar o tempo de cada ato ordinatório por processo.
# Filtra somente atos ordinatórios e soma por processo
bdsoma_ordinatorios <- atos_ate_denuncia %>%
filter(cod_movimento == 11383) %>% # filtra apenas atos ordinatórios
group_by(processo) %>% # agrupa por processo
summarise(soma_ordinatorios = sum(decorrencia, na.rm = TRUE))Agora temos um banco com a soma do tempo dos atos ordinatórios para cada processo, desde a distribuição até o recebimento da denúncia. Vamos analisar as estatísticas descritivas dessa variável.
# Estatísticas descritivas para a variável decorrencia_acumulada
tempo_stats <- bdsoma_ordinatorios %>%
summarise(
media = mean(soma_ordinatorios, na.rm = TRUE),
mediana = median(soma_ordinatorios, na.rm = TRUE),
desvio = sd(soma_ordinatorios, na.rm = TRUE),
variancia = var(soma_ordinatorios, na.rm = TRUE),
q1 = quantile(soma_ordinatorios, 0.25, na.rm = TRUE),
q3 = quantile(soma_ordinatorios, 0.75, na.rm = TRUE),
minimo = min(soma_ordinatorios, na.rm = TRUE),
maximo = max(soma_ordinatorios, na.rm = TRUE)
) |>
pivot_longer(
cols = everything(),
names_to = "Estatística",
values_to = "Valor"
)
# Tabela GT
tempo_stats %>%
gt() %>%
tab_header(
title = "Estatísticas Descritivas — Tempo médios dos Atos Ordinatórios até a Denúncia",
subtitle = "Variável: decorrencia"
) %>%
fmt_number(
columns = Valor,
decimals = 2
)| Estatísticas Descritivas — Tempo médios dos Atos Ordinatórios até a Denúncia | |
|---|---|
| Variável: decorrencia | |
| Estatística | Valor |
| media | 3.55 |
| mediana | 0.12 |
| desvio | 26.61 |
| variancia | 707.94 |
| q1 | 0.01 |
| q3 | 0.83 |
| minimo | 0.00 |
| maximo | 969.77 |
Observa-se que a mediana do tempo dos atos ordinatórios é muito baixa, cerca de 0,12 dias (aproximadamente 3 horas).
Entretanto, a média é significativamente maior, em torno de 3,5 dias, indicando que existem processos com atos ordinatórios muito longos, que elevam o valor médio. O desvio-padrão também é alto, reforçando que há grande variação entre os processos.
Esses resultados sugerem que é importante analisar mais detalhadamente os atos ordinatórios, especialmente nos processos que apresentam tempos excepcionalmente longos, para entender o que está causando essa discrepância.
Graficamente, a distribuição do tempo dos atos ordinatórios até a denúncia pode ser visualizada da seguinte forma:
ggplot(bdsoma_ordinatorios, aes(x = soma_ordinatorios)) +
geom_histogram(bins = 3000, fill = "#7185cc", color = "white", alpha = 0.7) +
geom_vline(aes(xintercept = mean(soma_ordinatorios)), color = "#c2986f", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 5, y = 750, vjust = -0.5, label = "Média", color = "#c2986f", fontface = "bold", size = 4) +
geom_vline(aes(xintercept = median(soma_ordinatorios)), color = "#c77878ff", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 2, y = 1000, vjust = -0.5, label = "Mediana", color = "#c77878ff", fontface = "bold", size = 4) +
labs(
x = "Tempo do Atos Ordinatórios",
y = "Frequência",
title = "Histograma do Tempo Atos Ordinatórios até a Denúncia"
) +
coord_cartesian(xlim = c(0, 25)) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10))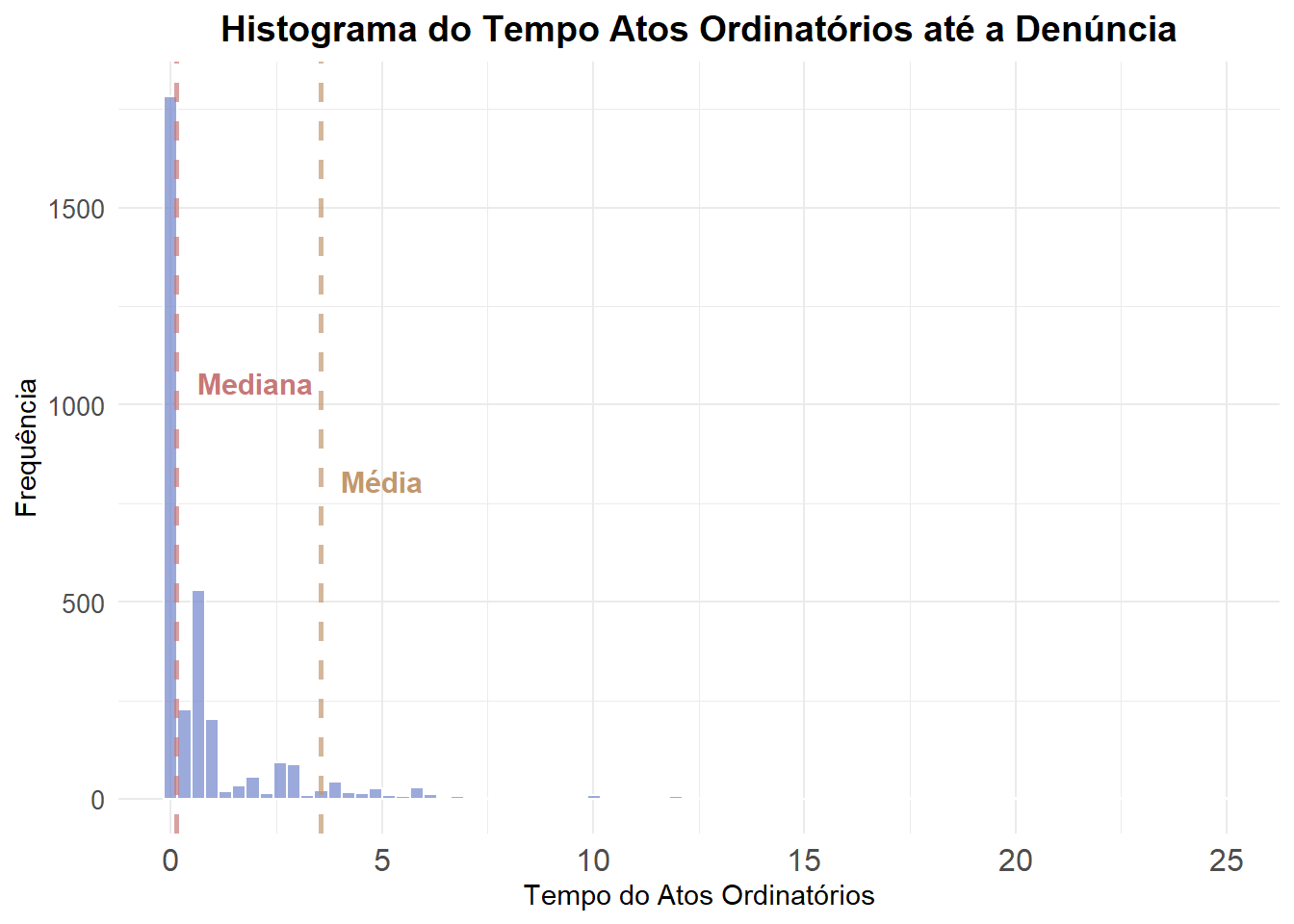
Como já visto a mediana da participação dos atos ordinatórios é 0,12 dias (aproximadamente 3 horas), enquanto a média é de 3,5 dias. A distribuição apresenta uma cauda longa à direita, evidenciando a presença de processos com atos ordinatórios excepcionalmente longos, que merecem análise detalhada.
Passamos a estudar a participação dos atos ordinatórios no tempo total entre distribuição e recebimento da denúncia.
O objetivo é entender:
- Quanto maior a participação, maior o tempo gasto entre a distribuição e denúncia?
- Como o tempo dos atos ordinatórios se relaciona com o tempo até a denúncia?
Para isso, abaixo apresentamos uma tabela que mostra, para cada processo, a participação dos atos ordinatórios e o tempo total entre distribuição e denúncia.
part_atos_ord <- t_denuncia_unico |>
left_join(bdsoma_ordinatorios, by = "processo") |>
mutate(
soma_ordinatorios = replace_na(soma_ordinatorios, 0),
participacao = (soma_ordinatorios) / deco_denuncia * 100)Agora temos um banco que mostra a participação dos atos ordinatórios no tempo total entre a distribuição e o recebimento da denúncia. Vamos analisar as estatísticas descritivas dessa participação.
# Scatterplot: Participação vs Deco_denúncia
ggplot(part_atos_ord, aes(x = soma_ordinatorios, y = deco_denuncia)) +
geom_point(color = "#7185cc", alpha = 0.6, size = 2) +
geom_smooth(method = "lm", color = "#c2986f", se = FALSE, linetype = "dashed") + # linha de tendência
labs(
x = "Participação dos Atos Ordinatórios (%)",
y = "Tempo até Denúncia (dias)",
title = "Relação entre Participação dos Atos Ordinatórios e Tempo até a Denúncia"
) +
coord_cartesian(xlim = c(0, 25), ylim = c(0, 100)) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10)
)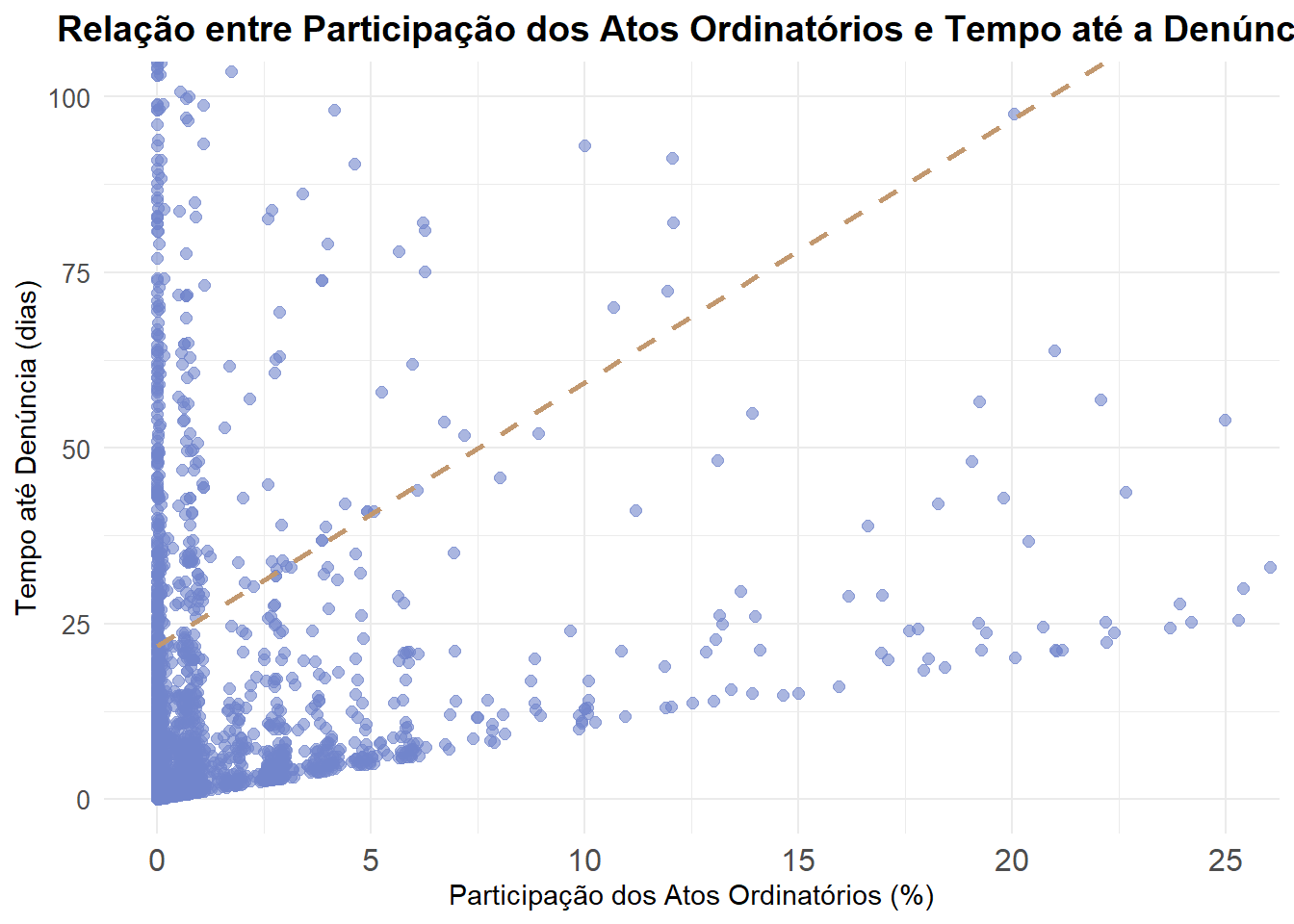
# Correlação entre participação e deco_denuncia
correlation <- cor(part_atos_ord$soma_ordinatorios, part_atos_ord$deco_denuncia, use = "complete.obs")
correlation[1] 0.5247109Observa-se que há uma relação positiva entre a participação dos atos ordinatórios e o tempo até a denúncia. Ou seja, quanto maior a participação dos atos ordinatórios, maior tende a ser o tempo até a denúncia. Entretanto a correlação não é alta, cerca de 0,52, indicando que outros fatores também influenciam o tempo até a denúncia.
Agora vamos explorar visiualmente se quanto maior a participação dos atos ordinatórios, maior é o tempo total até a denúncia. Primeiramente vamos analisar os processos com soma dos atos ordinatórios > 3 dias.
# Filtrar processos com soma dos atos ordinatórios > 30 dias
part_mais_3 <- part_atos_ord %>%
filter(soma_ordinatorios > 3)
# Histograma da participação
ggplot(part_mais_3, aes(x = participacao )) +
geom_histogram(binwidth = 5, fill = "#7185cc", color = "#7185cc", alpha = 0.4) +
labs(
x = "Participação dos Atos Ordinatórios (%)",
y = "Número de Processos",
title = "Distribuição da Participação dos Atos Ordinatórios (somente >3 dias)"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10)
)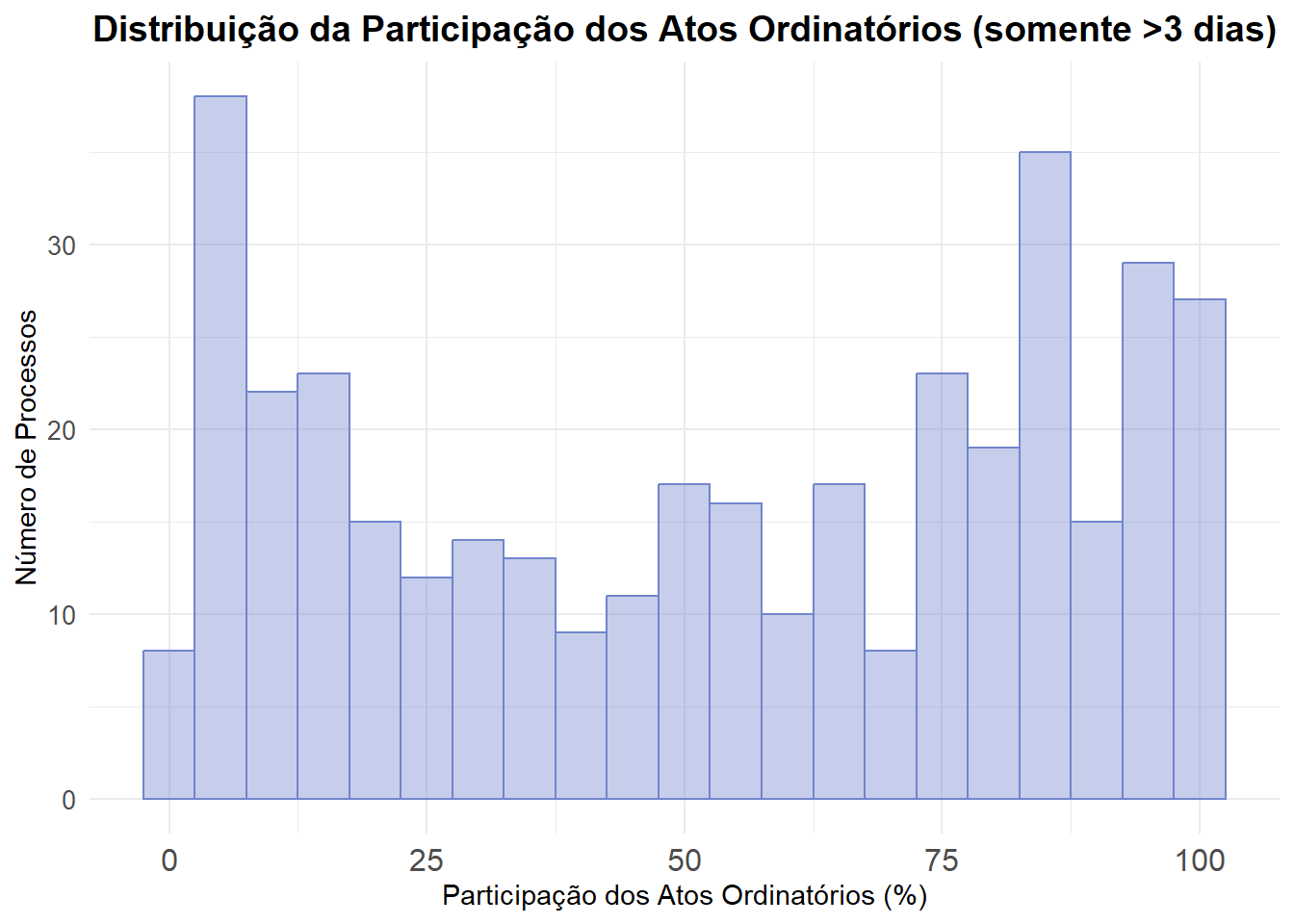
Observa-se que não há nenhum padrão claro, mostrando que a participação é próxima de uma distribuição uniforme para os processos com soma dos atos ordinatórios maior que 3 dias.
Abaixo mostramos nos processos com soma dos atos ordinatórios entre 1 e 3 dias.
# Filtrar processos com soma dos atos ordinatórios > 30 dias
part_menos_3 <- part_atos_ord %>%
filter(soma_ordinatorios <= 3 & soma_ordinatorios > 1)
# Histograma da participação
ggplot(part_menos_3, aes(x = participacao )) +
geom_histogram(binwidth = 5, fill = "#7185cc", color = "#7185cc", alpha = 0.4) +
labs(
x = "Participação dos Atos Ordinatórios (%)",
y = "Número de Processos",
title = "Distribuição da Participação dos Atos Ordinatórios (somente entre 1 e 3 dias)"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10)
)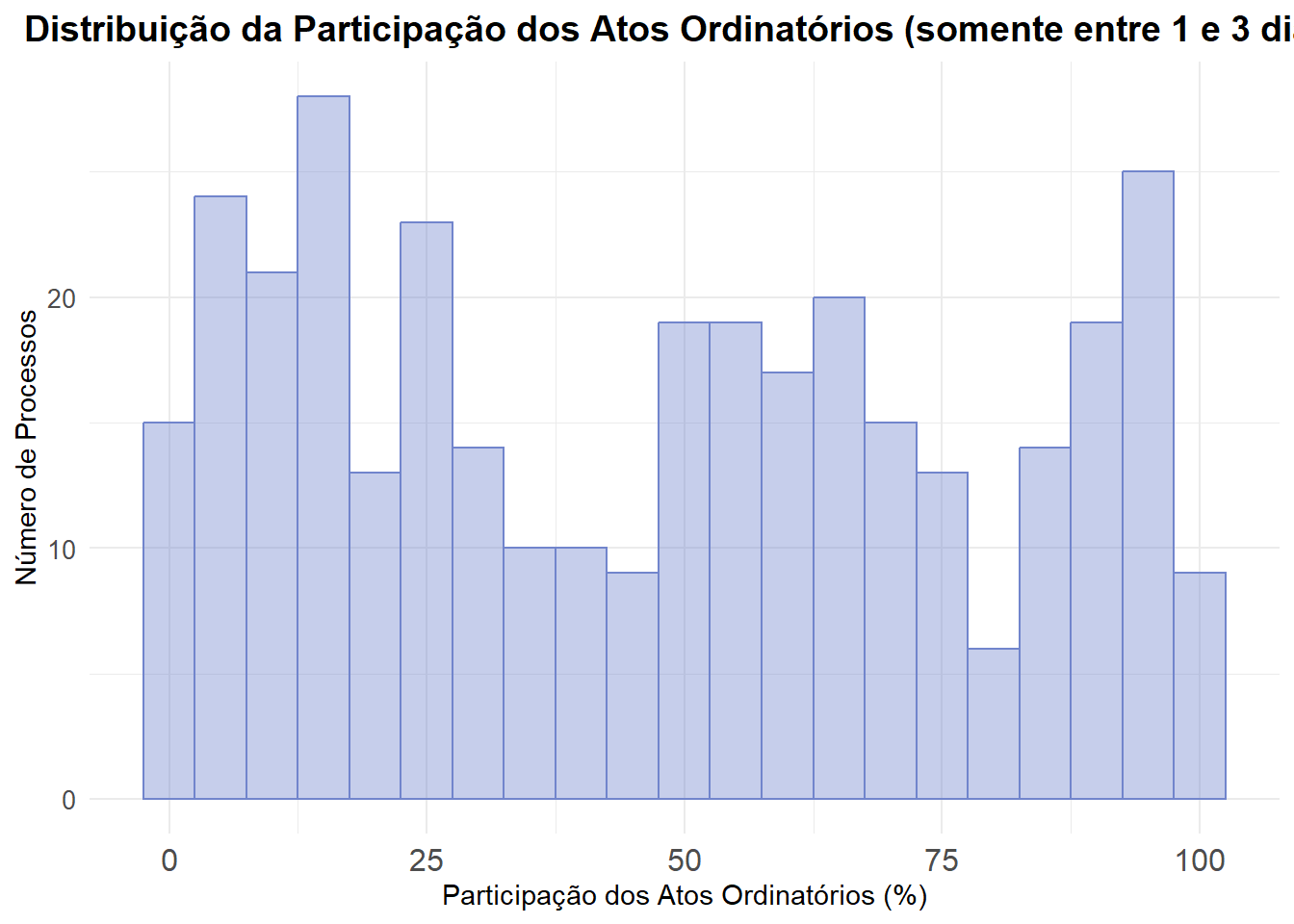
Novamente, observa-se que não há nenhum padrão claro para os processos com soma dos atos ordinatórios entre 1 e 3 dias.
REMESSA
Vamos somar o tempo de cada remessa por processo.
# Filtra somente atos ordinatórios e soma por processo
bdsoma_remessa <- atos_ate_denuncia %>%
filter(cod_movimento == 123) %>% # filtra apenas remessas
group_by(processo) %>% # agrupa por processo
summarise(soma_remessa = sum(decorrencia, na.rm = TRUE))Agora temos um banco com a soma do tempo das remessas para cada processo, desde a distribuição até o recebimento da denúncia. Vamos analisar as estatísticas descritivas dessa variável.
# Estatísticas descritivas para a variável decorrencia_acumulada
tempo_stats_r <- bdsoma_remessa %>%
summarise(
media = mean(soma_remessa, na.rm = TRUE),
mediana = median(soma_remessa, na.rm = TRUE),
desvio = sd(soma_remessa, na.rm = TRUE),
variancia = var(soma_remessa, na.rm = TRUE),
q1 = quantile(soma_remessa, 0.25, na.rm = TRUE),
q3 = quantile(soma_remessa, 0.75, na.rm = TRUE),
minimo = min(soma_remessa, na.rm = TRUE),
maximo = max(soma_remessa, na.rm = TRUE)
) |>
pivot_longer(
cols = everything(),
names_to = "Estatística",
values_to = "Valor"
)
# Tabela GT
tempo_stats_r %>%
gt() %>%
tab_header(
title = "Estatísticas Descritivas — Tempo médios das Remessas até a Denúncia",
subtitle = "Variável: decorrencia"
) %>%
fmt_number(
columns = Valor,
decimals = 2
)| Estatísticas Descritivas — Tempo médios das Remessas até a Denúncia | |
|---|---|
| Variável: decorrencia | |
| Estatística | Valor |
| media | 12.70 |
| mediana | 0.00 |
| desvio | 73.70 |
| variancia | 5,431.73 |
| q1 | 0.00 |
| q3 | 0.11 |
| minimo | 0.00 |
| maximo | 1,009.18 |
Observa-se que a mediana do tempo dos das remessas é muito baixa, em zero 0,00 dias (aproximadamente 3 horas).
Entretanto, a média é significativamente maior, em torno de 12,76 dias, indicando que existem processos com remessas muito longos, que elevam o valor médio. O desvio-padrão também é alto, reforçando que há grande variação entre os processos.
Graficamente, a distribuição do tempo dos atos ordinatórios até a denúncia pode ser visualizada da seguinte forma:
ggplot(bdsoma_remessa, aes(x = soma_remessa)) +
geom_histogram(bins = 3000, fill = "#7185cc", color = "white", alpha = 0.7) +
geom_vline(aes(xintercept = mean(soma_remessa)), color = "#c2986f", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 5, y = 750, vjust = -0.5, label = "Média", color = "#c2986f", fontface = "bold", size = 4) +
geom_vline(aes(xintercept = median(soma_remessa)), color = "#c77878ff", size = 1, alpha = 0.7,linetype = "dashed") +
annotate("text", x = 2, y = 1000, vjust = -0.5, label = "Mediana", color = "#c77878ff", fontface = "bold", size = 4) +
labs(
x = "Tempo do Atos Ordinatórios",
y = "Frequência",
title = "Histograma do Tempo Atos Ordinatórios até a Denúncia"
) +
coord_cartesian(xlim = c(0, 25)) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10))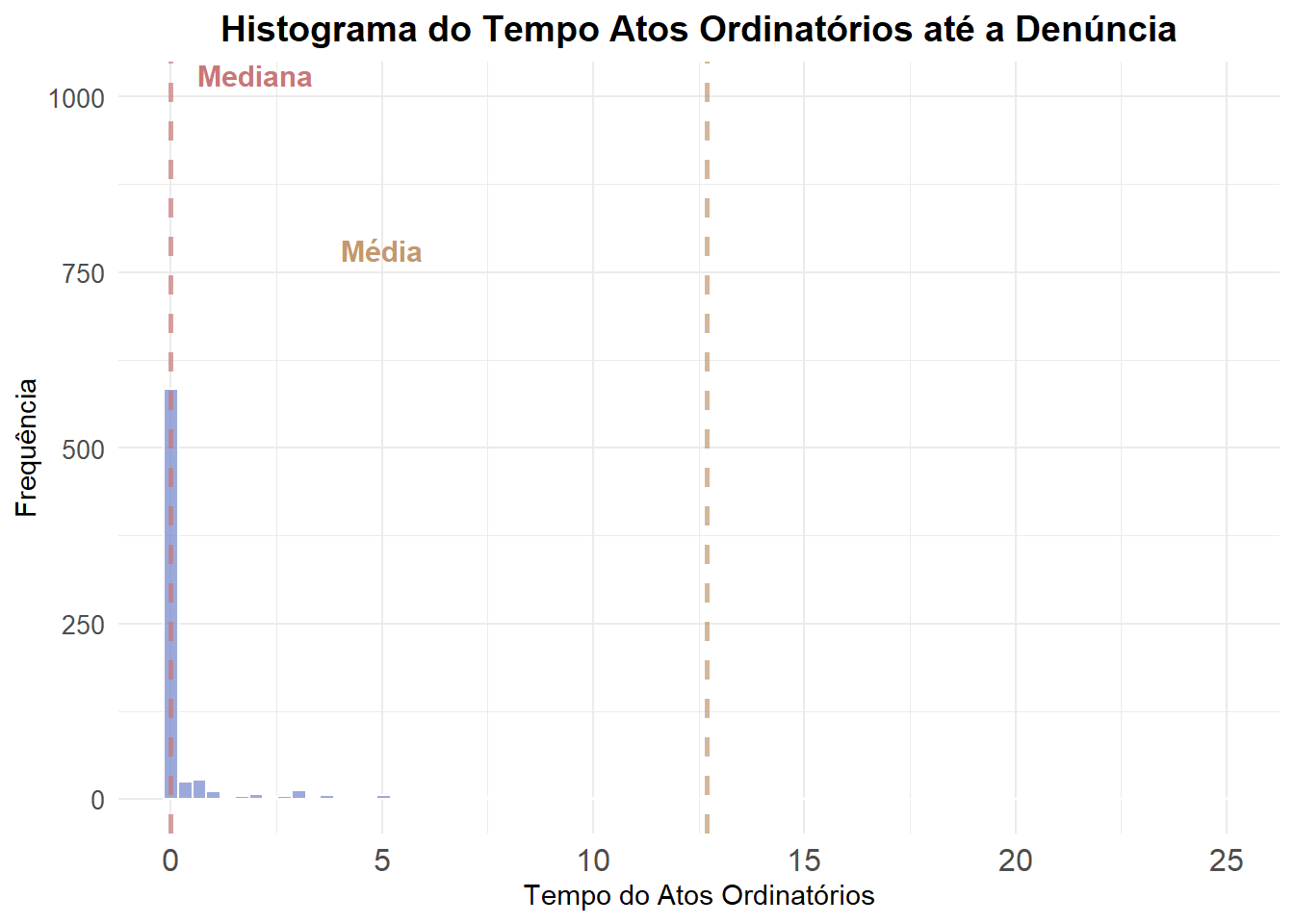
Como já visto a mediana da participação dos atos ordinatórios é 0,12 dias (aproximadamente 3 horas), enquanto a média é de 3,5 dias. A distribuição apresenta uma cauda longa à direita, evidenciando a presença de processos com atos ordinatórios excepcionalmente longos, que merecem análise detalhada.
Passamos a estudar a participação dos atos ordinatórios no tempo total entre distribuição e recebimento da denúncia.
O objetivo é entender:
- Quanto maior a participação, maior o tempo gasto entre a distribuição e denúncia?
- Como o tempo dos atos ordinatórios se relaciona com o tempo até a denúncia?
Para isso, abaixo apresentamos uma tabela que mostra, para cada processo, a participação dos atos ordinatórios e o tempo total entre distribuição e denúncia.
part_remessa_ord <- part_atos_ord |>
left_join(bdsoma_remessa, by = "processo") |>
mutate(
soma_remessa = replace_na(soma_remessa, 0),
part_remessa = (soma_remessa) / deco_denuncia * 100)part_remessa_ord$soma_remessa[is.na(part_remessa_ord$soma_remessa)] <- 0
part_remessa_ord$part_remessa[is.na(part_remessa_ord$part_remessa)] <- 0Agora temos um banco que mostra a participação dos atos ordinatórios no tempo total entre a distribuição e o recebimento da denúncia. Vamos analisar as estatísticas descritivas dessa participação.
# Scatterplot: Participação vs Deco_denúncia
ggplot(part_remessa_ord, aes(x = soma_remessa, y = deco_denuncia)) +
geom_point(color = "#7185cc", alpha = 0.6, size = 2) +
geom_smooth(method = "lm", color = "#c2986f", se = FALSE, linetype = "dashed") + # linha de tendência
labs(
x = "Participação dos Atos Ordinatórios (%)",
y = "Tempo até Denúncia (dias)",
title = "Relação entre Participação dos Atos Ordinatórios e Tempo até a Denúncia"
) +
coord_cartesian(xlim = c(0, 25), ylim = c(0, 100)) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10)
)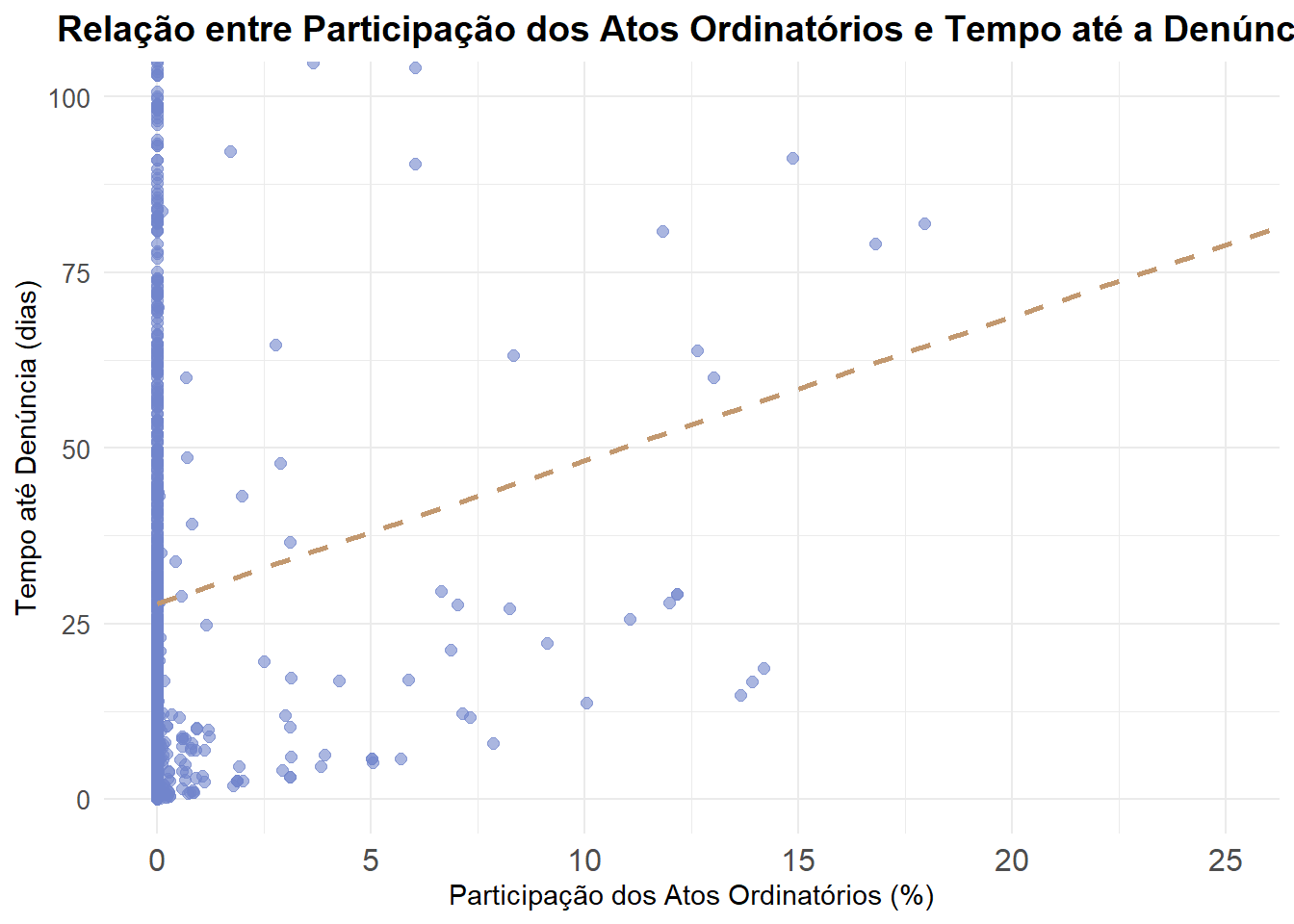
# Correlação entre participação e deco_denuncia
correlation <- cor(part_remessa_ord$soma_remessa, part_remessa_ord$deco_denuncia, use = "complete.obs")
correlation[1] 0.3784582Observa-se que há uma relação positiva entre a participação das remessas e o tempo até a denúncia. Ou seja, quanto maior a participação dos atos ordinatórios, maior tende a ser o tempo até a denúncia. Entretanto a correlação não é alta, cerca de 0,37, indicando que outros fatores também influenciam o tempo até a denúncia.
Agora vamos explorar visiualmente se quanto maior a participação dos atos ordinatórios, maior é o tempo total até a denúncia. Primeiramente vamos analisar os processos com soma dos remessas > 5 dias.
# Filtrar processos com soma dos atos ordinatórios > 30 dias
part_mais_3_r <- part_remessa_ord %>%
filter(soma_remessa > 10)
# Histograma da participação
ggplot(part_mais_3_r, aes(x = part_remessa )) +
geom_histogram(binwidth = 5, fill = "#7185cc", color = "#7185cc", alpha = 0.4) +
labs(
x = "Participação dos Atos Ordinatórios (%)",
y = "Número de Processos",
title = "Distribuição da Participação dos Atos Ordinatórios (somente >3 dias)"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10)
)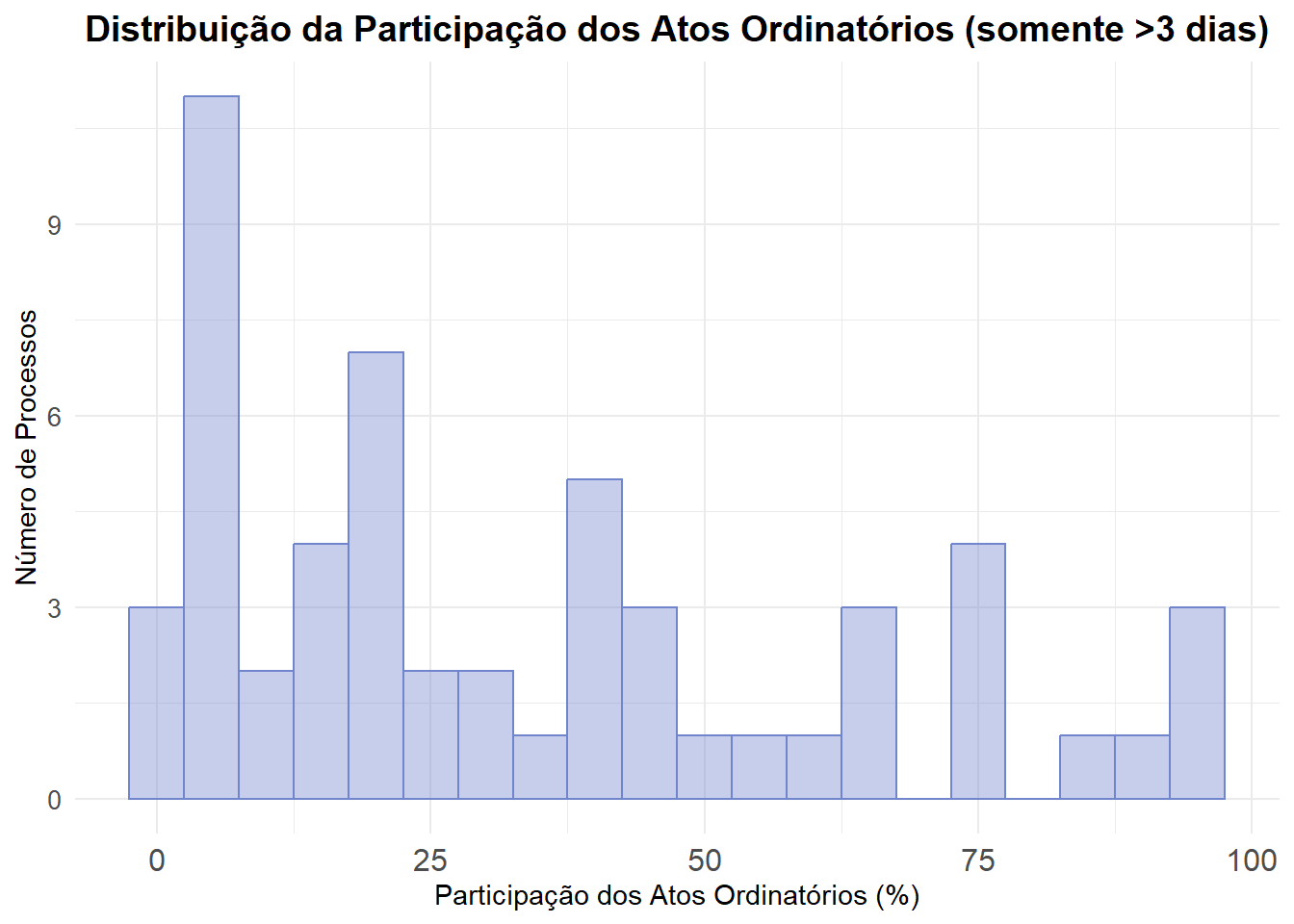
Observa-se que não há nenhum padrão claro, mostrando que a participação é próxima de uma distribuição uniforme para os processos com soma dos atos ordinatórios maior que 3 dias.
Abaixo mostramos nos processos com soma dos atos ordinatórios entre 2 e 10 dias.
# Filtrar processos com soma dos atos ordinatórios
part_menos_10_r <- part_remessa_ord %>%
filter(soma_remessa <= 10 & soma_remessa > 2)
# Histograma da participação
ggplot(part_menos_10_r, aes(x = participacao )) +
geom_histogram(binwidth = 5, fill = "#7185cc", color = "#7185cc", alpha = 0.4) +
labs(
x = "Participação dos Atos Ordinatórios (%)",
y = "Número de Processos",
title = "Distribuição da Participação dos Atos Ordinatórios (somente entre 1 e 3 dias)"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 10)
)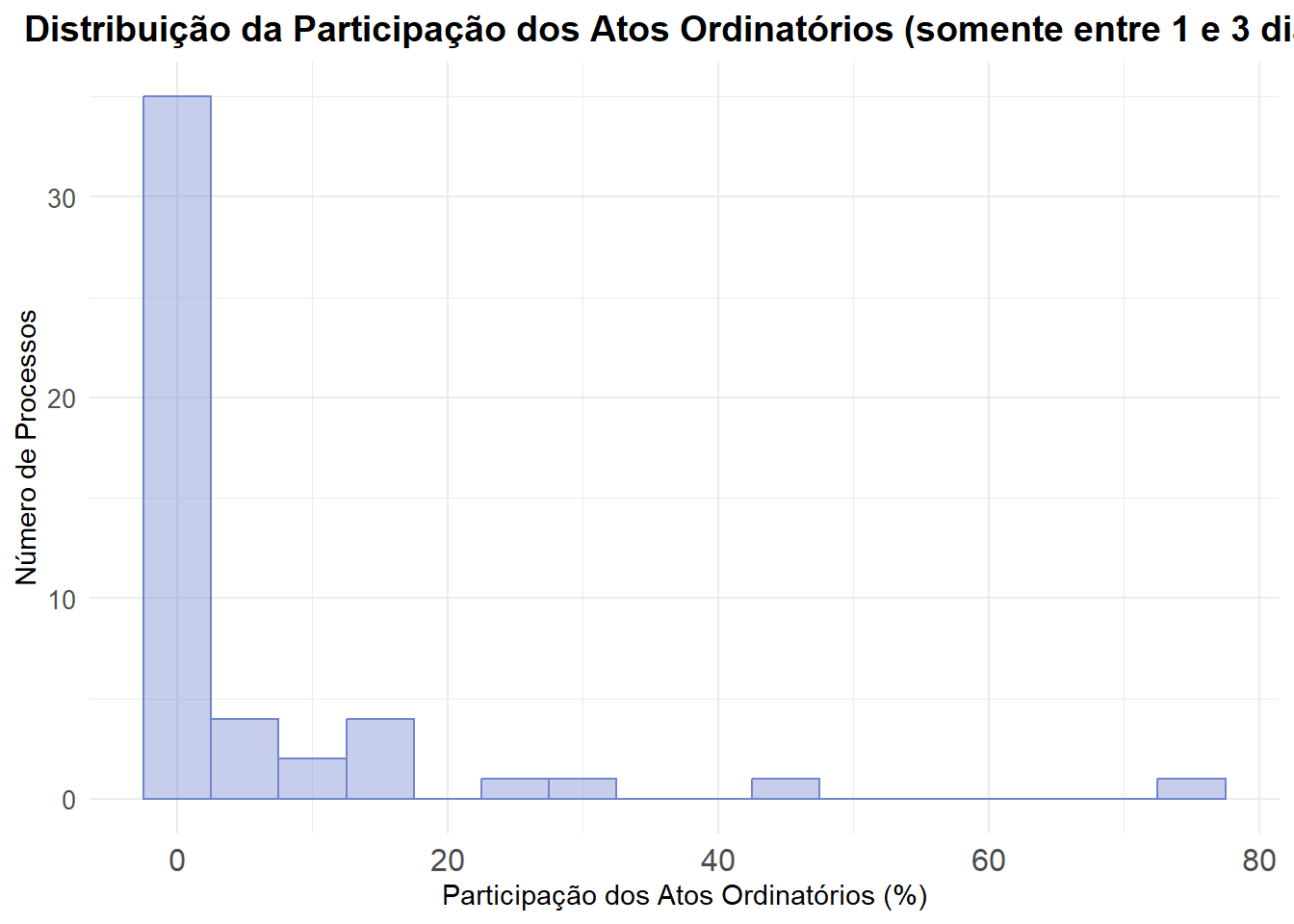
Vamos analisar juntos os Atos Ordinatórios e as Remessas para entender melhor o que está acontecendo nesses processos que apresentam tempos longos entre a distribuição e o recebimento da denúncia.
contagens <- atos_ate_denuncia |>
summarise(
n_remessa = sum(cod_movimento == 123),
n_ordinatorio = sum(cod_movimento == 11383),
.by = processo
)
part_remessa_ord <- part_remessa_ord |>
left_join(contagens, by = "processo")
dados_q <- part_remessa_ord |>
mutate(
quantil_tempo = ntile(deco_denuncia, 4) # cria Q1..Q4
)
resumo_quantil <- dados_q |>
summarise(
media_tempo_total = mean(deco_denuncia, na.rm = TRUE),
media_soma_remessa = mean(soma_remessa, na.rm = TRUE),
media_soma_ordinatorio = mean(soma_ordinatorios, na.rm = TRUE),
media_n_remessa = mean(n_remessa, na.rm = TRUE),
media_n_ordinatorio = mean(n_ordinatorio, na.rm = TRUE),
.by = quantil_tempo
)
resumo_quantil |>
arrange(quantil_tempo) |>
gt() |>
tab_header(
title = "Processos mais longos têm mais remessas e atos ordinatórios?"
) |>
fmt_number(
columns = where(is.numeric),
decimals = 2
) |>
cols_label(
quantil_tempo = "Quantil Tempo",
media_tempo_total = "Tempo Denúncia (média)",
media_soma_remessa = "Tempo Remessa (média)",
media_soma_ordinatorio = "Tempo Atos Ordin. (média)",
media_n_remessa = "Nº de Remessas (média)",
media_n_ordinatorio = "Nº de Atos Ordin. (média)"
)